このドキュメントでは、OSS 検索エンジンである Vespa の使い方について紹介します。
|
チュートリアルのコードは以下のリポジトリにあります。 |
1. Vespa 環境の構築
このセクションでは、 QuickStart の中で利用されている Docker イメージ vespaengine/vespa の処理を追うことで、Vespa の具体的な構築手順について見ていきます。
|
この構築手順は CentOS7 での実行を想定しています。 また、クラスタまで構築する場合は最低でも 8GB 程度のメモリを持つ環境が必要となります。 |
1.1. Vespa のインストール
Dockerfile を見ると分かるように、Vespa は現在 rpm パッケージとして提供されています。
Vespa を yum 経由でインストールするためには、まず Vespa のリポジトリを yum に追加する必要があります。
以下のように yum-config-manager を用いて group_vespa-vespa-epel-7.repo を追加します。
# yum-config-manager --add-repo https://copr.fedorainfracloud.org/coprs/g/vespa/vespa/repo/epel-7/group_vespa-vespa-epel-7.repo次に、Vespa の依存パッケージをインストールします。
# yum install epel-release
# yum install centos-release-scl最後に、Vespa 本体をインストールします。
# yum install vespaVespa パッケージは /opt/vespa 配下にインストールされます。
$ ls /opt/vespa
bin conf etc include lib lib64 libexec man sbin share|
Vespa 関連のコマンドは また、Vespa 関連のログは |
1.2. Vespa の起動
Vespa の構成を大雑把に図にまとめると以下のようになります (公式ドキュメントだと この辺)。
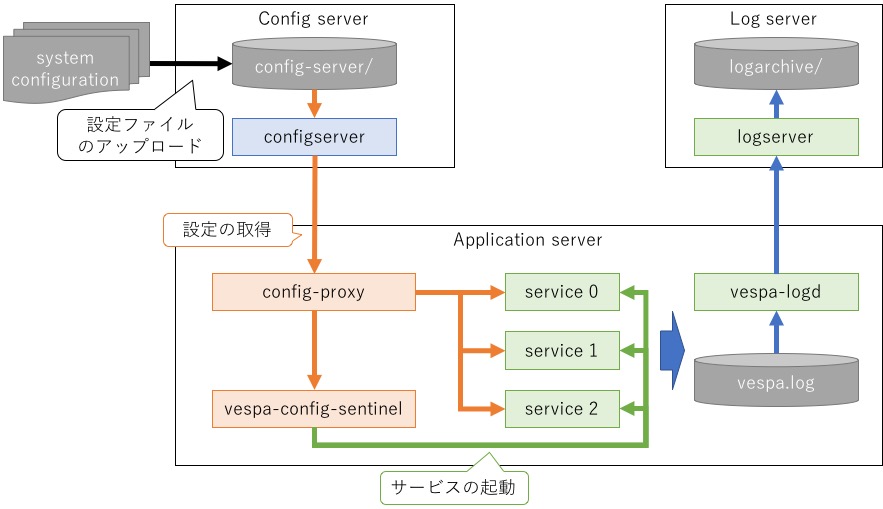
Vespa で起動されるプロセスは大きく分けて3つのグループに分けられます。
-
configserver(図の 青色 のプロセス群)-
いわゆる ZooKeeper のことで、クラスタ内で参照される設定ファイル群を管理
-
-
vespa-config-sentinel(図の 赤色 のプロセス群)-
各アプリケーションサーバにて対応するサービスプロセスを管理
-
config-proxyを介してconfigserverから情報を取得します
-
-
service(図の 緑色 のプロセス群)-
実際の検索処理を担当するプロセス群
-
設定ファイルを元に必要なプロセスが
vespa-config-sentinelによって起動されます
-
このうち実際の処理に対応する service は、後述の設定ファイルのデプロイにて起動されるプロセスとなります。
この時点ではまだ設定ファイルが登録されていないため、この節では configserver と config-sentinel の2つが対象となります。
start-container.sh を見ると分かるように、Vespa の起動は大きくわけて3つのステップに分けられます。
-
環境変数の設定
-
configserverの起動 -
vespa-config-sentinelの起動
|
以降のコマンドの実行ユーザは各環境の設定に応じて変更してください。
チュートリアルでは |
1.2.1. 環境変数の設定
初めに、各 Vespa ノードで
VESPA_CONFIGSERVERS
という環境変数に configserver のアドレスを指定する必要があります。
# export VESPA_CONFIGSERVERS=${host1},${host2},...この環境変数が明示的に指定されていない場合、localhost がデフォルト値として利用されます。
1.2.2. configserver の起動
次に、VESPA_CONFIGSERVERS にて指定したホスト上で以下のコマンドを実行し、configserver を起動します。
# /opt/vespa/bin/vespa-start-configserver起動後、以下のように2つのプロセスが起動していることが確認できます。
# ps aux | grep vespa | grep -v grep
vespa 571 0.0 0.4 97620 70704 ? Ss 07:09 0:00 vespa-runserver -s configserver -r 30 -p /opt/vespa/var/run/configserver.pid -- java -Xms128m -Xmx2048m -XX:+PreserveFramePointer -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/vespa/var/crash -XX:OnOutOfMemoryError=kill -9 %p -Djava.library.path=/opt/vespa/lib64 -Djava.awt.headless=true -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.net.client.defaultConnectTimeout=5000 -Dsun.net.client.defaultReadTimeout=60000 -Djavax.net.ssl.keyStoreType=JKS -Djdisc.config.file=/opt/vespa/var/jdisc_core/configserver.properties -Djdisc.export.packages= -Djdisc.cache.path=/opt/vespa/var/vespa/bundlecache/configserver -Djdisc.debug.resources=false -Djdisc.bundle.path=/opt/vespa/lib/jars -Djdisc.logger.enabled=true -Djdisc.logger.level=ALL -Djdisc.logger.tag=jdisc/configserver -Dfile.encoding=UTF-8 -Dzookeeperlogfile=/opt/vespa/logs/vespa/zookeeper.configserver.log -cp /opt/vespa/lib/jars/jdisc_core-jar-with-dependencies.jar com.yahoo.jdisc.core.StandaloneMain standalone-container-jar-with-dependencies.jar
vespa 572 55.6 3.9 4110952 655828 ? Sl 07:09 0:15 java -Xms128m -Xmx2048m -XX:+PreserveFramePointer -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/vespa/var/crash -XX:OnOutOfMemoryError=kill -9 %p -Djava.library.path=/opt/vespa/lib64 -Djava.awt.headless=true -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.net.client.defaultConnectTimeout=5000 -Dsun.net.client.defaultReadTimeout=60000 -Djavax.net.ssl.keyStoreType=JKS -Djdisc.config.file=/opt/vespa/var/jdisc_core/configserver.properties -Djdisc.export.packages= -Djdisc.cache.path=/opt/vespa/var/vespa/bundlecache/configserver -Djdisc.debug.resources=false -Djdisc.bundle.path=/opt/vespa/lib/jars -Djdisc.logger.enabled=true -Djdisc.logger.level=ALL -Djdisc.logger.tag=jdisc/configserver -Dfile.encoding=UTF-8 -Dzookeeperlogfile=/opt/vespa/logs/vespa/zookeeper.configserver.log -cp /opt/vespa/lib/jars/jdisc_core-jar-with-dependencies.jar com.yahoo.jdisc.core.StandaloneMain standalone-container-jar-with-dependencies.jar|
この2つのプロセスは以下のように親子関係になっています。 Vespa のプロセスはこのように vespa-runserver から fork される形式で起動されます。 |
1.2.3. vespa-config-sentinel の起動
最後に、各 Vespa ノードにて 以下のコマンドを実行し、 vespa-config-sentinel を起動します。
# /opt/vespa/bin/vespa-start-services起動後、以下のように新たに4つのプロセスが起動していることが確認できます。
# ps aux | grep vespa | grep -v configserver | grep -v grep
vespa 1079 0.0 0.0 25604 708 ? Ss 07:27 0:00 vespa-runserver -r 10 -s configproxy -p var/run/configproxy.pid -- java -Xms32M -Xmx256M -XX:ThreadStackSize=256 -XX:MaxJavaStackTraceDepth=-1 -XX:OnOutOfMemoryError=kill -9 %p -Dproxyconfigsources=tcp/localhost:19070 -cp libexec/vespa/patches/configproxy:lib/jars/config-proxy-jar-with-dependencies.jar com.yahoo.vespa.config.proxy.ProxyServer 19090
vespa 1080 0.8 0.2 1740948 44500 ? Sl 07:27 0:00 java -Xms32M -Xmx256M -XX:ThreadStackSize=256 -XX:MaxJavaStackTraceDepth=-1 -XX:OnOutOfMemoryError=kill -9 %p -Dproxyconfigsources=tcp/localhost:19070 -cp libexec/vespa/patches/configproxy:lib/jars/config-proxy-jar-with-dependencies.jar com.yahoo.vespa.config.proxy.ProxyServer 19090
vespa 1148 0.0 0.0 25604 700 ? Ss 07:27 0:00 vespa-runserver -s config-sentinel -r 10 -p var/run/sentinel.pid -- sbin/vespa-config-sentinel -c hosts/76eae592a196
vespa 1149 0.1 0.0 66552 4480 ? Sl 07:27 0:00 sbin/vespa-config-sentinel -c hosts/76eae592a196|
この4つのプロセスも |
|
もし、 |
1.3. チュートリアル環境の構築
本チュートリアルでは、ここまで見てきた Dockerfile を用いて実際に Docker 上に Vespa を構築します。
|
実行には |
必要な設定はチュートリアルに付属の docker-compose.xml に定義されているため、
以下のように docker-compose を用いてコンテナを起動します。
$ git clone https://github.com/yahoojapan/vespa-tutorial
$ cd vespa-tutorial
$ sudo docker-compose up -d起動が完了したら、付属のスクリプトを用いて環境のステータスを確認します。
$ utils/vespa_status
configuration server ... [ OK ]
application server (vespa1) ... [ NG ]
application server (vespa2) ... [ NG ]
application server (vespa3) ... [ NG ]この時点ではまだ設定ファイルがなく、
service が起動していないため configserver のみが OK となります。
|
|
2. Vespa の設定
このセクションでは、Vespa の具体的な設定方法について見ていきます。
|
複数ノードを使ったクラスタの構成については Vespa とクラスタリング を参照してください。 |
2.1. 設定ファイル
Vespa の設定ファイルは以下のようなディレクトリ構成で定義されます。
myconfig/
|- hosts.xml
|- services.xml
|- searchdefinitions/
| |- myindex.sd
| `- ...
|- components/
| |- myplugin.jar
| `- ...
`- search/query-profiles/
`- myprofile.xml各設定ファイルにはそれぞれ以下のような役割があります。
| 設定ファイル | 役割 |
|---|---|
Vespa クラスタに所属する host 名の一覧。 |
|
Vespa で起動するサービスの定義。 |
|
Vespa で扱うインデックスの定義。 |
|
components |
Vespa で利用するプラグイン ( |
検索クエリに付与するデフォルトパラメタの定義。 |
このうち最低限必要となるのは hosts.xml、services.xml、searchdefinitions の3つです。
2.1.1. hosts.xml
hosts.xml には Vespa クラスタに所属するホスト名の定義を記述します。
例えば、チュートリアルの sample-apps/config/basic/hosts.xml では以下のように記述されています。
<?xml version="1.0" encoding="utf-8" ?>
<hosts>
<host name="vespa1">
<alias>node1</alias>
</host>
</hosts>上記例のように、hosts.xml ではノードのホスト名を name 属性で、
後述の services.xml で参照されるエイリアス名を alias 要素でそれぞれ定義します。
|
|
2.1.2. services.xml
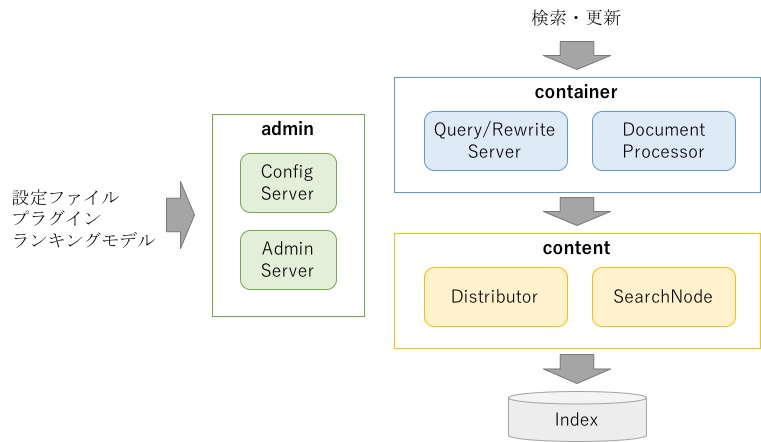
services.xml には Vespa の各ノードがどのようなサービスを起動するかの設定を記述します。
Vespa のサービスは
admin、
container、
content
の3つに大別されます
|
サービスを含めて Vespa で起動されるプロセスの一覧は以下のページに記載されています。 なお、Vespa は |
|
実際は他にもサービスがいますが、ここでは動作上必要な前述の3つのみに対象を絞って説明します。 他のサービスの設定については 公式ドキュメント を参照してください。 |
admin
Vespa クラスタの管理サービスで、
チュートリアルの sample-apps/config/basic/services.xml では以下のように記述されています。
<admin version="2.0">
<adminserver hostalias="node1"/>
<configservers>
<configserver hostalias="node1"/>
</configservers>
<logserver hostalias="node1"/>
<slobroks>
<slobrok hostalias="node1"/>
</slobroks>
</admin>それぞれの要素は以下のようなサービスを意味しています。
| 要素 | 役割 |
|---|---|
adminserver |
管理ノード本体を担当するサーバで、admin コマンドの実行ノードになります (たぶん)。 |
configservers |
ZooKeeper に対応するサーバ群で、設定ファイルの管理を行います。複数ノードを指定することで冗長化が可能です。 |
logserver |
Vespa のログ収集を担当するサーバで、Vespa クラスタ内の全サービスのログをアーカイブします。 |
slobroks |
|
|
これ以外にも ` cluster-controllers`、 |
container
Vespa のフロントエンドに対応するサービスで、
チュートリアルの sample-apps/config/basic/services.xml では以下のように記述されています。
<container id="container" version="1.0">
<component id="jp.co.yahoo.vespa.language.lib.kuromoji.KuromojiLinguistics"
bundle="kuromoji-linguistics">
<config name="language.lib.kuromoji.kuromoji">
<mode>search</mode>
<ignore_case>true</ignore_case>
</config>
</component>
<document-api/>
<document-processing/>
<search/>
<nodes>
<node hostalias="node1"/>
</nodes>
</container>container はユーザからの検索リクエストや更新リクエストを受け付ける層に対応しています。
上記の設定の場合、セクションの中身は大きく以下の3つのグループに分解できます。
-
component -
document-api,document-processing,search -
nodes
component は追加モジュールの定義で、
ここでは日本語の形態素解析器に対応する KuromojiLinguistics というモジュールを追加しています。
|
より具体的には、 |
|
|
document-api、document-processing および search はコンテナ上に起動する各種サービスに対応しており、
それぞれ以下のような機能を有効化します。
| 要素 | 機能 |
|---|---|
document-api |
更新リクエストのための Document API を有効にします。 |
document-processing |
更新対象のドキュメントに対する加工処理 ( |
search |
検索リクエストのための Search API を有効化します。 |
|
デフォルトでは |
|
Vespa の 公式チュートリアル の設定では
|
nodes ではこのコンテナ定義を適用するノードの一覧を記述しています。
チュートリアルのサンプルでは全ノードに対して同一の設定を適用していますが、
ノード毎に container セクションを別々に定義することで個別に設定を行うことも可能です。
|
|
content
Vespa のインデックス本体を持つノードで、
チュートリアルの sample-apps/config/basic/services.xml では以下のように記述されています。
<content id="book" version="1.0">
<redundancy>1</redundancy>
<documents>
<document type="book" mode="index"/>
<document-processing cluster="container"/>
</documents>
<nodes>
<node hostalias="node1" distribution-key="0"/>
</nodes>
</content>redundancy はドキュメントの冗長数のことで、インデックス中にドキュメントの複製をいくつ保持するかを指定します。
|
Vespa ではインデックスを |
documents はインデックスの具体的な定義に対応する設定で、参照するスキーマ定義および前処理の参照先を指定しています。
document 要素の type は後述の searchdefitions に記述されたスキーマ定義の識別子を指定しています。
また、mode はインデックスの保持方法を選択しており、通常の全文検索の場合は mode=index となります。
document-processing では対応する前処理が実行される container の識別子を指定します (ここでは前述の "container" が対応)。
|
|
nodes は container と同じように構築対象のノードを指定しています。
distribution-key はドキュメントを分散させるときの配置先決めに利用される値で、
全てのノードで異なるキーとなるように設定します。
|
ノードの追加・削除で という3ノード構成から "node2" を外す場合、新しい設定は以下のようになります。 |
2.1.3. searchdefinitions
searchdefinitions
では Vespa の検索に関する定義のことで、.sd という拡張子のファイルとなっています。
searchdefinitions の中身は独自のフォーマットで書かれており、具体的には以下のような情報が記載されています。
-
スキーマ定義 (document)
-
検索対象のフィールド群のエイリアス定義 (fieldset)
-
リランキングのためのモデル定義 (rank-profile)
ここでは document と fieldset の2つについて説明します (モデル定義については
Vespa とランキング
で説明)。
|
|
|
公式ドキュメント を見ると分かるように、実際にはもっと色々な定義が可能ですが、ここではよく使う項目に対象を絞っています。 |
document
document はスキーマ定義に対応する項目で、
チュートリアルの sample-apps/config/basic/searchdefinitions/book.sd では以下のように記述されています。
document book {
field language type string {
indexing: "ja" | set_language
}
field title type string {
indexing: summary | index
summary-to: simple_set, detail_set
}
field desc type string {
indexing: summary | index
summary-to: detail_set
}
field price type int {
indexing: summary | attribute
summary-to: simple_set, detail_set
}
field page type int {
indexing: summary | attribute
}
field genres type array<string> {
indexing: summary | attribute
summary-to: detail_set
}
field reviews type weightedset<string> {
indexing: summary | attribute
}
}各 field 要素はスキーマに存在するフィールドの定義に対応しています。
ただし、一番上の language だけは特殊で、ドキュメントが日本語 (ja) であることを明示的に宣言しています。
field では以下のように名称 (name)、型 (type)、処理方法 (indexing) の3つの項目でフィールドを定義するのが基本となります。
|
|
field ${name} type ${type} {
indexing: ${indexing}
}type には代表的なものとして以下のような型が指定できます (詳細は
こちら
を参照)。
| 型 | 説明 |
|---|---|
string |
文字列型、処理方法によって形態素解析の有無が変わります。 |
integer |
32-bit 整数の数値型、単一の値を保持します。 |
long |
64-bit 整数の数値型、単一の値を保持します。 |
byte |
8-bit 整数の数値型、単一の値を保持します。 |
float |
単精度浮動小数点型、単一の値を保持します。 |
double |
倍精度浮動小数点型、単一の値を保持します。 |
array<element-type> |
配列型、 |
weightedset<element-type> |
辞書型、 |
indexing には以下の3つが指定できます (詳細は
こちら
を参照)。
| 処理 | 説明 |
|---|---|
attribute |
値をオンメモリ上に展開します (ソートやグルーピングで用いるフィールドに指定)。 |
index |
形態素解析してインデックスに登録します ( |
summary |
レスポンスに指定されたフィールドの値を付与します |
チュートリアルの例のように、これらの設定は summary | index と組み合わせて利用できます。
ただし、attribute と index は対の関係にあるため、通常は attribute と index を同時に指定することはないです。
基本的に index は文章のような長い文字列型にのみ指定し、
それ以外の数値型やキーワードのような単一文字列については attribute を用います。
|
より正確にいうと、 |
fieldset
fieldset は複数のフィールドを束ねたエイリアスの定義に利用します。
チュートリアルの sample-apps/config/basic/searchdefinitions/book.sd では以下のように記述されています。
fieldset default {
fields: title, desc
}上記のように定義した場合、検索時に query=default:foo と検索フィールドとして
fieldset の名称を指定することで、紐付いているフィールド全体に対して検索したのと同じ意味になります。
|
|
2.2. Vespa へのデプロイ
設定ファイルの Vespa への反映には vespa-deploy というコマンドを用います。
ここでは、シングルノード用の設定である sample-apps/config/basic を実際にデプロイする手順を追っていきます。
|
事前に チュートリアル環境の構築 の手順に従って Vespa を起動しておいてください。 |
2.2.1. 日本語トークナイザの配置
現在の Vespa は日本語トークナイザを内包していないため、
対応する jar を別途入手して components 配下に配置する必要があります。
container の節で述べたように、ここでは KuromojiLinguistics を利用します。
KuromojiLinguistics は
vespa-kuromoji-linguistics
にて公開されている Vespa のプラグインで、
文書のトークン分けに Kuromoji を利用する実装となっています。
Kuromoji はJavaで実装されたオープンソースの日本語形態素解析エンジンで、 Solr や Elasticsearch でも日本語トークナイザとして採用されています。
|
|
本チュートリアルでは、事前に用意した以下のスクリプトを用いて kuromoji-linguistics.jar をセットアップします。
$ sample-apps/plugin/setup.sh (1)
$ ls sample-apps/plugin/ (2)
kuromoji-linguistics.jar setup.sh vespa-kuromoji-linguistics| 1 | リポジトリからソースをダウンロードし、パッケージをビルド |
| 2 | kuromoji-lingustics.jar としてプラグインが配置されます |
|
チュートリアルでは、 |
2.2.2. 設定ファイルのアップロード
起動した Vespa ノードのうち、vespa1 にログインします。
$ sudo docker-compose exec vespa1 /bin/bashチュートリアル環境では Docker コンテナの /vespa-sample-apps に sample-apps/ がマウントされています。
[root@vespa1 /]# ls /vespa-sample-apps/
config feed plugin以下のコマンドを実行し、/vespa-sample/apps/config/basic を configserver にアップロードします。
[root@vespa1 /]# vespa-deploy prepare /vespa-sample-apps/config/basic/
Uploading application '/vespa-sample-apps/config/basic/' using http://vespa1:19071/application/v2/tenant/default/session?name=basic
Session 2 for tenant 'default' created.
Preparing session 2 using http://vespa1:19071/application/v2/tenant/default/session/2/prepared
Session 2 for tenant 'default' prepared.このように、設定ファイルの Vespa へのアップロードは次のコマンドで実行します。
vespa-deploy prepare ${config}もし、設定ファイルに不備がある場合、prepare は失敗し、エラーログがコンソールに出力されます。
|
上記コマンドは、内部的には以下の2つのコマンドを実行しています。 |
2.2.3. 設定ファイルの反映
次に、以下のコマンドを実行し、アップロードした設定を実際に Vespa に反映させます。
[root@vespa1 /]# vespa-deploy activate
Activating session 2 using http://vespa1:19071/application/v2/tenant/default/session/2/active
Session 2 for tenant 'default' activated.
Checksum: a60feb4256b6f0051b462252b6b398ad
Timestamp: 1518510769258
Generation: 2これにより、各 Vespa に最新の設定が行き渡り、しばらくすると対応するサービスが起動します。
試しに 8080 ポートから検索を行うと、0件 ("totalCount":0) と結果が返ってきます。
[root@vespa1 /]# curl 'http://localhost:8080/search/?query=foo'
{"root":{"id":"toplevel","relevance":1.0,"fields":{"totalCount":0},"coverage":{"coverage":100,"documents":0,"full":true,"nodes":0,"results":1,"resultsFull":1}}}Ctrl-D でコンテナを抜けて utils/vespa_status を実行すると、
先程 NG だった vespa1 が OK に変わっていることが確認できます。
$ utils/vespa_status
configuration server ... [ OK ]
application server (vespa1) ... [ OK ]
application server (vespa2) ... [ NG ]
application server (vespa3) ... [ NG ]3. Vespa と更新
このセクションでは、Vespa にドキュメントを登録する方法について見ていきます。
3.1. 更新リクエスト
Vespa では更新リクエストは以下のように JSON を用いて記述します。
|
ここで紹介しているフォーマットは後述の Client を用いて一括更新を行うケースを想定しています。 |
{
{
"put": "id:book:book::foo",
"fields": {
...
}
},
{
"update": "id:book:book::bar",
"fields": {
...
}
},
{
"remove": "id:book:book::foo"
},
...
}各ドキュメントの先頭に記載された put、update、`remove`はそれぞれ追加、更新、削除の操作を意味しており、
それぞれ値として対象のドキュメント ID を指定します。
3.1.1. ドキュメント ID
ドキュメント ID のフォーマットは以下のように定義されています ( Documents )。
id:<namespace>:<document-type>:<key/value-pairs>:<user-specified>ドキュメント ID の各要素はそれぞれ以下のような意味があります。
| 要素 | 必須? | 意味 |
|---|---|---|
namespace |
o |
ドキュメントの名前空間、複数ユーザで Vespa をシェアしていたりするときに混在しないように付与します。 |
document-type |
o |
対象のインデックス名、 |
key/value-pairs |
ドキュメントを特定のbucket (i.e., ノード) に偏らせたいときに指定します。 |
|
user-specified |
o |
ユーザ指定のユニークな ID を指定します。 |
例えば、book インデックスに "foo" という ID で登録する場合は以下のように指定します。
id:book:book::foo|
|
|
|
3.1.2. put
put は新規ドキュメントの追加もしくは上書きを行います。
以下のように対象のフィールドとその値のペアを fields の要素として定義していきます。
{
"put": "id:book:book::foo",
"fields": {
"title": "fizz buzz",
...
}
}各フィールドの値の書き方は、対応するフィールドのスキーマ定義によって以下のように変わります( Document JSON format - Put )。
// 文字列型 (string)
"title": "fizz buzz"
// 数値型 (integer, long, byte, float, double)
"price": 3000
// 配列型 (ここでは array<string> の例)
"genres": [
"foo",
"bar"
]
// 辞書型 (ここでは weightedset<string> の例)
"reviews": {
"foo": 100,
"bar": 50
}|
Vespa の配列型フィールドでは feed 上での定義順が保持されたままインデックスされます。
上の例の場合、 |
|
|
3.1.3. update
update は既存ドキュメントの部分更新を行います。
以下のように対象のフィールドとそこへの操作のペアを fields の要素として定義していきます。
{
"update": "id:book:book::foo",
"fields": {
"title": {
"assign": "buzz fizz"
}
}
}上記例の assign の部分は更新方法の指定を行っており、以下の3つが指定できます (
Document JSON format - Update
)。
| 方法 | 動作 |
|---|---|
assign |
フィールドの値を指定した値で上書きします。 |
add |
フィールドに指定した値を追加します (配列型や辞書型で利用可能)。 |
remove |
指定したフィールドの値を削除します。 |
3.1.4. remove
remove は既存ドキュメントの削除を行います。
remove ではドキュメント ID のみが必要なため、fields のような追加の要素の定義は不要です。
{
"remove": "id:book:book::foo"
}|
インデックスから全ドキュメントを削除したい場合は、Vespa のサービスを停止した状態で vespa-remove-index を叩くことで全削除できます。 |
3.2. ドキュメントの更新
Vespa では更新リクエストの投げ方には以下のような2つの方法が用意されています。
本ドキュメントでは、後者の Client を用いた方法でドキュメントの登録を行います。
|
実運用では、一括更新が可能な Client ( vespa-feeder ) を利用する方が一般的かと思います。 |
3.2.1. Client の実行方法
Vepsa では Client プログラムを実行ラッパーとして vespa-feeder というコマンドが提供されています。
vespa_feeder では以下のように、引数として更新リクエストの json ファイルをわたすことで Vespa へのドキュメントの登録が行えます。
$ vespa_feeder documents.json3.2.2. サンプルデータの登録
チュートリアルでは、サンブルデータとして前述の book インデックス向けに以下のようなドキュメントが用意されています。
$ cat sample-apps/feed/book-data-put.json
[
{
"put": "id:foo:book:g=foo:vespa_intro",
"fields": {
"title": "ゼロから始めるVespa入門",
"desc": "話題のOSS検索エンジン、Vespaの使い方を初心者にもわかりやすく解説します",
"price": 1500,
"page": 200,
"genres": [
"コンピュータ"
"検索エンジン",
"Vespa"
],
"reviews": {
"quality": 40,
"readability": 90,
"cost": 80
}
}
},
...まず、前節で起動した vespa1 にログインします。
$ sudo docker-compose exec vespa1 /bin/bash次に、マウントされている /vespa-sample-apps 配下にあるサンプルデータを vespa-feeder を用いて登録します。
[root@vespa1 /]# vespa-feeder /vespa-sample-apps/feed/book-data-put.json
Messages sent to vespa (route default) :
----------------------------------------
PutDocument: ok: 13 msgs/sec: 46.93 failed: 0 ignored: 0 latency(min, max, avg): 212, 219, 215これでドキュメントの登録は完了です。
試しに以下のコマンドで検索を行うと、
"totalCount":13 と登録されたドキュメントが返却されることが確認できます。
[root@vespa1 /]# curl 'http://localhost:8080/search/?query=sddocname:book'
{"root":{"id":"toplevel","relevance":1.0,"fields":{"totalCount":13}, ...|
|
|
feed されたドキュメントはレスポンスが返った時点で検索から見えるようになります。 また、トランザクションログのディスクへの書き出しの周期は OS 依存となっていて、典型的には 30 秒程度で反映されます。 詳しくは Vespa consistency model を参照してください。 |
4. Vespa と検索
このセクションでは、Vespa での検索方法について見ていきます。
4.1. 検索クエリ
Vespa では検索クエリの指定方法として大きく2つのフォーマットが提供されています。
本ドキュメントでは、このうち Search API の方に対象を絞って紹介します。
|
|
Search API を用いて検索を行う場合、URL は以下のようなパスとなります。
http://${host]:8080/search/?p1=v1&p2=v2&...Vespa Search API reference
にあるように、Search API では様々なパラメタが定義されていますが、ここでは基本的なものとして以下のパラメタについて説明します。
| パラメタ | 役割 |
|---|---|
language (lang) |
クエリの言語を指定します。 |
query |
検索クエリを指定します。 |
hits (count) |
返却するドキュメントの件数を指定します。 |
offset (start) |
返却するドキュメントの開始位置を指定します。 |
sorting |
検索結果をソートする条件を指定します。 |
filter |
検索対象を絞り込むためのフィルタ条件を指定します (ランキング計算にも影響)。 |
recall |
検索対象を絞り込むためのフィルタ条件を指定します。 |
summary |
レスポンスに含めるフィールドのセットを指定します。 |
format |
レスポンスのフォーマットを指定します。 |
timeout |
検索リクエストのタイムアウト時間 (ms) を指定します。 |
tracelevel |
レスポンスに付与するデバッグ情報のレベル (1-9) を指定します。 |
|
Vespaのアクセスログは 後ろの |
|
|
4.1.1. language (lang)
language はクエリの言語指定を行うためのパラメタで、日本語での検索を行う際に重要です。
Vespa では、デフォルトでは検索クエリは英語 (en) であると解釈され、英語用のクエリ解析が行われます。
日本語で検索を行う場合は、以下のように language パラメタを用いて言語が日本語 (ja) であることを指定する必要があります。
search/?language=ja&query=ほげ例えば、今回のサンプルデータの場合、以下の2つのクエリで検索結果に差異があることが確認できます。
// ヒットなし
search/?query=入門書
// 1件ヒット
search/?language=ja&query=入門書これは、前者では言語が英語と認識されているために、"入門書"がトークナイズされずそのまま検索クエリとして投げられているのに対し、 後者では言語が日本語となっているため、"/入門/書/"と2つのトークンに正しく分割されるという違いがあるためです。
|
トークナイズされたトークンは内部的には AND 検索として扱われます。
例えば |
4.1.2. query
query は実際の検索クエリを指定するパラメタです。
指定できる記法は
Simple Query Language Reference
となっていますが、典型的なものをピックアップすると以下のようになります。
| 内容 | クエリ |
|---|---|
defaultフィールドに対して"foo"を検索 |
|
titleフィールドに対して"foo"を検索 (フィールド指定検索) |
|
"foo"かつ"bar"を含むものを検索 (AND検索) |
|
"foo"もしくは"bar"を含むものを検索 (OR検索) |
|
"foo"を含むが"bar"を含まないものを検索 (NOT検索) |
|
"foo bar"というフレーズを検索 (フレーズ検索) |
|
|
|
"foo"に150%の重みを付与して検索 (重み付き検索) |
|
|
重み付き検索は Solr や Elasticsearch における |
|
Vespa では |
4.1.3. hits (count), offset (start)
hits と offset は検索結果のうちどの範囲を取得するかを指定します。
例えば、hits=20 かつ offset=10 と指定した場合、
最終的に得られた検索結果のうち、上から数えて11番目から30番目までの計20件を取得することを意味しています。
|
この例の場合、内部的には以下のような動きになります。
|
4.1.4. sorting
sorting では検索結果をソートするときのルールを指定します。
sorting の記法は
Query result sorting
にまとめられていますが、基本的には以下のようにフィールド名に + か - を付けて指定します。
// priceの昇順 ("+") でソート
select/?language=ja&q=入門&sorting=+price
// priceの降順 ("-") でソート
select/?language=ja&q=入門&sorting=-price
// priceの降順 ("-") でソートし、同一priceはpageの昇順 ("+") でソート
select/?language=ja&q=入門&sorting=-price +page
// relevancy (スコア) の降順でソート
select/?language=ja&q=入門&sorting=-[rank]上記例のように、スペース区切りで複数の条件を並べることで多段にソートを行うことができます。
また、[rank] と指定した場合は特別な意味があり、これは文書の relevancy (ランキングのスコア) が参照されます。
なお、sorting が明示的に指定されていない場合は sorting=-[rank] がデフォルトで指定されます。
4.1.5. filter, recall
filter と recall は検索クエリ (query) とは別に検索対象を絞る条件を追加する目的で利用されます。
イメージとしては、
-
filterおよびrecallの条件式にマッチするドキュメントの集合を取得 -
queryの条件にマッチするドキュメントをその集合から選択
というような動作となります。
filter と recall では query で用いたシンタックスがそのまま使えますが、
以下のように各クエリの先頭に + および - を付ける必要があります。
// titleに"python"を含む ("+") ドキュメントの中から、"入門"を含むものを選択
select/?language=ja&q=入門&filter=+title:python
select/?language=ja&q=入門&recall=+title:python
// titleに"python"を含まない ("-") ドキュメントの中から、"入門"を含むものを選択
select/?language=ja&q=入門&filter=-title:python
select/?language=ja&q=入門&recall=-title:python|
実際にURLとして指定するときは |
filter と recall は
「filter のフィルタ条件はランキングのスコア計算に影響するが、recall の方は影響しない」
という点で異なります。
例えば、filter=+title:python と指定した場合、title に python を含むかどうかがスコアに影響を与えます。
一方、recall=+title:python と指定した場合は単純にドキュメントのフィルタとして機能し、スコアには影響を与えません。
なお、filter には + と - の指定の他に、以下のように「なにも付けない」という指定も可能です。
// titleに"python"を含むかどうかをスコア計算で考慮
select/?language=ja&q=入門&filter=title:pythonこの場合、filter で指定した条件はドキュメントのヒット判定には影響しませんが、
ランキングのスコア計算のときに考慮されるようになります。
例えば、特定の単語を含むドキュメントのスコアを底上げしたい、のようなスコア調整をする際にこの記法が有効です。
|
このような AND 条件を指定したい場合は、以下のように一つのクエリとして表現する必要があります。 |
4.1.6. summary
summary はレスポンスに含めるフィールドのセットを指定します。
Vespa では、
searchdefinitions
の中で各フィールドが所属する
summary-class
を定義することでフィールドのセットを作成できます。
summary-class の定義の方法は大きく2つあります。
1つ目は各フィールドに以下のような summary-to 属性を付与して所属するセット名を指定する方法です。
field title type string {
indexing: index | summary
summary-to: simple_set, detail_set (1)
}| 1 | title フィールドを simple_set と full_set というセットに追加 |
2つ目は以下のように document-summary というブロックで所属するフィールド群を指定する方法です。
search book {
...
document-sumamry simple-set {
summary simple_set type string { (1)
source: title, price
}
summary detail_set type string { (2)
source: title, desc, price, genres
}
}
}| 1 | title と price を含む simple_set というセットを定義 |
| 2 | title、desc、price、genres を含む detail_set というセットを定義 |
検索では以下のように定義したセット名を summary として指定します。
search/?language=ja&query=入門&summary=simple_set4.1.7. format
format はレスポンスのフォーマットの指定を行います。
Vespa はデフォルトでは json フォーマットでレスポンスを返しますが、
例えば format=xml と指定すると xml フォーマットでレスポンスが返却されます。
|
レスポンスのフォーマットは独自の |
4.1.8. timeout
timeout では検索リクエストのタイムアウト時間を指定します。
Vespa ではデフォルトで 5000 ミリ秒のタイムアウトが設定されています。
もし、このタイムアウト時間を変更したい場合は、このパラメタにタイムアウト時間をミリ秒で指定して検索を行います。
ちなみに、検索がタイムアウトした場合は以下のように Timed out とレスポンスが返されます。
[root@vespa1 /]# curl 'http://localhost:8080/search/?query=java&timeout=0'
{"root":{"id":"toplevel","relevance":1.0,"fields":{"totalCount":0},"errors":[{"code":12,"summary":"Timed out","source":"book","message":"The search chain 'book' timed out."}]}}4.1.9. tracelevel
tracelevel は検索リクエストのデバッグを行うときに指定するパラメタです。
Vespa では内部でこの tracelevel の値に応じてデバッグログのレスポンスへの付与を制御しています。
tracelevel は 1 から 9 までの9段階の指定が可能で、高いほどより詳細なログが出力されるようになります。
|
のように、最終的に検索されるクエリに差異があることがわかります。 |
4.2. グルーピング検索
Vespa では他の検索エンジンと同様に グルーピング検索 の機能を提供しています。 Vespa のグルーピング機能は他の検索エンジンに比べて高機能で、 これだけで多種多様な集約系の処理が表現可能となっています。
4.2.1. グルーピングの構文
Vespa のグルーピングの構文は公式ドキュメントの Query result grouping reference にまとめられています。 記載されている文法を見ると分かるように、非常に複雑なものとなっています。
実際に例を見ながら構文を説明していきます。
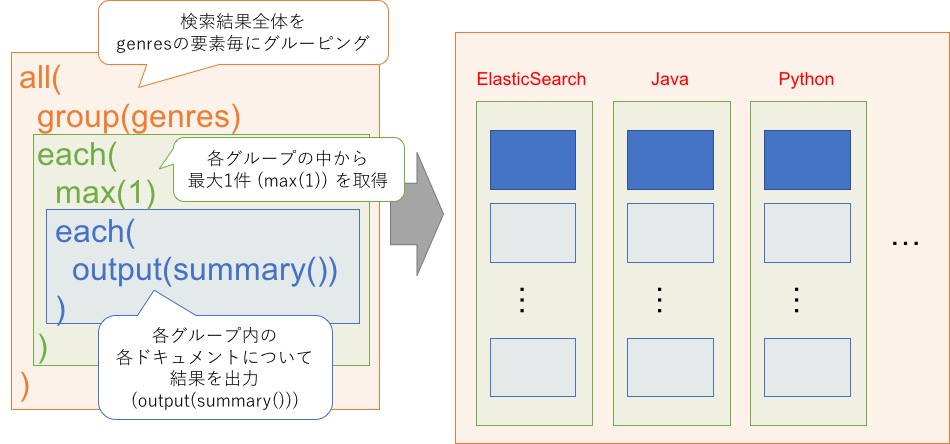
まず、サンプルデータに対して「genres の各要素毎にドキュメントを一つ選択して表示」を行う場合、
検索リクエストは以下のようになります。
search/?language=ja&query=sddocname:book&select=all(group(genres) each(max(1) each(output(summary()))))実際に検索すると、レスポンスに "id": "group:root:0" という要素が増えていることが確認できます。
また、 "id": "group:root:0" の children の下に各ジャンルに紐づくドキュメントが1件ずつ出力されます。
|
非常に長い |
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:genres",
"relevance": 1,
"label": "genres",
"children": [
{
"id": "group:string:Elasticsearch",
"relevance": 0,
"value": "Elasticsearch",
"children": [
{
"id": "hitlist:hits",
"relevance": 1,
"label": "hits",
"children": [
{
"id": "id:foo:book:g=foo:elasticsearch_science",
"relevance": 0,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Elasticsearchで始めるデータサイエンス",
"desc": "Elasticsearchとデータサイエンスツールとの連携について紹介します",
"price": 3000,
...先程の検索リクエストの中で、グルーピングに関する部分は select パラメタになります。
select パラメタの中身を整形すると以下のようになります。
all(
group(genres)
each(
max(1)
each(
output(summary())
)
)
)グルーピングの構文を理解するには、まず all と each を理解することが第一歩です。
外側の all は検索結果全体への操作を、内部の each はそれぞれ各グループおよび各ドキュメントへの操作を表しています。
上記の操作を図にすると以下のようなイメージとなります。
Vespa のグルーピングはこのように、
-
allもしくはeachを指定して対象を選択する -
選択対象に対する操作を記述する
-
1.に戻る
というように再帰的な手順を踏んで定義していきます。
all は後述の group 操作を行うときに指定が必要で、例えば多段のグルーピングを行うときに複数回出現します (
具体例
参照)。
each はグルーピングで選ばれた要素に対して操作を行うときに利用します。
定義できる操作は対象がドキュメントの集合 (グループ) なのか、それとも単一のドキュメントなのか、
によって利用可否が決まるため、ルールを記述するときは今の選択範囲がどこなのかを意識することが重要となります。
グルーピングの対象は group(field_name) のように定義します。
上記例では genres という配列型のフィールドを対象としています。
|
グルーピングの対象として配列型のフィールドを指定した場合、 Vespa では配列中の各要素を独立なものとして集約処理が実施されます。 配列型要素のうち、特定のインデックスの要素が欲しい場合は、
|
上記例の中の max(1) はそのグループから最大で1件の結果を取得する事を意味しています。
初めの each の中で定義されているため、この操作の対象は各グループのドキュメント群となります。
最後に output(summary()) はドキュメントの検索結果を出力することを意味しています。
2つ目の each の中で定義されているため、この操作の対象は各グループの各ドキュメントとなります。
output は検索レスポンスへの情報の付与に対応していて、
例えばグループを対象としている階層なら output(avg(price)) のような統計値を指定もできます。
summary はドキュメントを対象としているときに指定できる操作で、前述のようにドキュメントの内容の参照に対応しています。
4.2.2. グルーピングの具体例
前述のように、Vespa のグルーピングは each で対象を絞りつつ、各グループ or ドキュメントに対して操作を定義していくというものでした。
ここでは、実際に具体例を見ながら Vespa のグルーピングでできる機能について紹介していきます。
|
ここの具体例は代表的なものだけをピックアップしていますが、 Vespa のグルーピングではより複雑な処理も記述できます。 より詳細な機能を知りたい場合は Query result grouping reference に記載されている Example も併せて参照してください。 |
グループの並び順の変更
Vespa のグルーピングでは、order という操作を用いてグループの並び順を制御できます。
例えば、各ジャンルについて所属するドキュメントの価格の最大値が高いものから順に表示したい場合は以下のような式となります。
all(
group(genres) (1)
order(-max(price)) (2)
each(
output(max(price)) (3)
)
)| 1 | genres の値についてグルーピング |
| 2 | 各グループの price の最大値の降順でソート |
| 3 | 結果がわかりやすいように各グループの price の最大値を出力 |
order は得られたグループをどのように並び替えるかを指定するための式です。
この例では、max(price) から各グループの price 最大値が、
-max(price) と - がついてることから降順であることがわかります。
|
|
これを例えば query=title:入門 と組み合わせると、検索クエリは以下のようになります。
search/?language=ja&query=title:入門&select=all(group(genres) order(-max(price)) each(output(max(price))))結果、以下のようにタイトルに 入門 が含まれるドキュメントについて、価格の最大値が高い順のジャンルのグループが得られます。
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:genres",
"relevance": 1,
"label": "genres",
"children": [
{
"id": "group:string:Python",
"relevance": 1,
"value": "Python",
"fields": {
"max(price)": 2000
}
},
{
"id": "group:string:コンピュータ",
"relevance": 0.8,
"value": "コンピュータ",
"fields": {
"max(price)": 2000
}
},
{
"id": "group:string:プログラミング",
"relevance": 0.6,
"value": "プログラミング",
"fields": {
"max(price)": 2000
}
},
{
"id": "group:string:Vespa",
"relevance": 0.4,
"value": "Vespa",
"fields": {
"max(price)": 1500
}
},
{
"id": "group:string:検索エンジン",
"relevance": 0.2,
"value": "検索エンジン",
"fields": {
"max(price)": 1500
}
}
]
}
]
},各グループの統計情報の取得
前述の max(price) のように、Vespa のグルーピングではグループ内の統計情報を取得するための操作が定義されています。
例えば、genres の各グループについて、 price の合計、平均、最小、最大、標準偏差を出力する場合は以下のような式になります。
all(
group(genres)
order(-count()) (1)
each(
output(sum(price)) (2)
output(avg(price)) (3)
output(min(price)) (4)
output(max(price)) (5)
output(stddev(price)) (6)
)
)| 1 | グループをヒット件数 (count()) の降順で並び替え |
| 2 | price の合計値 (sum) を出力 |
| 3 | price の平均値 (avg) を出力 |
| 4 | price の最小値 (min) を出力 |
| 5 | price の最大値 (max) を出力 |
| 6 | price の標準偏差 (stddev) を出力 |
これを例えば query=title:入門 と組み合わせると、検索クエリは以下のようになります。
search/?language=ja&query=title:入門&select=all(group(genres) order(-count()) each(output(sum(price)) output(avg(price)) output(min(price)) output(max(price)) output(stddev(price))))結果、以下のように各ジャンルでの price の統計値が出力されます。
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:genres",
"relevance": 1,
"label": "genres",
"children": [
{
"id": "group:string:コンピュータ",
"relevance": 1,
"value": "コンピュータ",
"fields": {
"sum(price)": 3500,
"avg(price)": 1750,
"min(price)": 1500,
"max(price)": 2000,
"stddev(price)": 250
}
},
...|
上の例では、レスポンスのラベルが
|
各グループに対するヒット数および検索結果を取得
いわゆる faceting や result grouping に対応する処理も、
Vespa ではグルーピング式を用いて定義します。
例えば、genres の各グループについて、ヒット数と上位3件を表示する場合は以下のような式になります。
all(
group(genres)
order(-count())
each(
max(3) (1)
output(count() as(total)) (2)
each(
output(summary()) (3)
)
)
)| 1 | 各グループから最大で3件を取得 |
| 2 | 各グループのヒット数 (count()) を "total" というラベル (as(total)) で取得 |
| 3 | 各ドキュメントの情報 (summary()) を出力 |
これを例えば query=title:入門 と組み合わせると、検索クエリは以下のようになります。
search/?language=ja&query=title:入門&select=all(group(genres) order(-count()) each(max(3) output(count() as(total)) each(output(summary()))))結果、以下のように各ジャンルでのヒット数と検索結果が出力されます。
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:genres",
"relevance": 1,
"label": "genres",
"children": [
{
"id": "group:string:コンピュータ",
"relevance": 1,
"value": "コンピュータ",
"fields": {
"total": 2
},
"children": [
{
"id": "hitlist:hits",
"relevance": 1,
"label": "hits",
"children": [
{
"id": "id:book:book::python_intro",
"relevance": 0.15974580091895013,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Python本格入門",
"desc": "今話題のPythonの使い方をわかりやすく説明します",
"price": 2000,
"page": 450,
"genres": [
"コンピュータ",
"プログラミング",
"Python"
],
"reviews": [
{
"item": "readability",
"weight": 80
},
{
"item": "cost",
"weight": 70
},
{
"item": "quality",
"weight": 50
}
],
"documentid": "id:book:book::python_intro"
}
},
{
"id": "id:book:book::vespa_intro",
"relevance": 0.15968230614070084,
"source": "book",
"fields": {
"sddocname": "book",
"title": "ゼロから始めるVespa入門",
"desc": "話題のOSS検索エンジン、Vespaの使い方を初心者にもわかりやすく解説します",
"price": 1500,
"page": 200,
"genres": [
"コンピュータ",
"検索エンジン",
"Vespa"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 80
},
{
"item": "quality",
"weight": 40
}
],
"documentid": "id:book:book::vespa_intro"
}
}
]
}
]
},
{
"id": "group:string:Python",
"relevance": 0.8,
"value": "Python",
"fields": {
"total": 1
},
"children": [
{
"id": "hitlist:hits",
"relevance": 1,
"label": "hits",
"children": [
{
"id": "id:book:book::python_intro",
"relevance": 0.15974580091895013,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Python本格入門",
"desc": "今話題のPythonの使い方をわかりやすく説明します",
"price": 2000,
"page": 450,
"genres": [
"コンピュータ",
"プログラミング",
"Python"
],
"reviews": [
{
"item": "readability",
"weight": 80
},
{
"item": "cost",
"weight": 70
},
{
"item": "quality",
"weight": 50
}
],
"documentid": "id:book:book::python_intro"
}
}
]
}
]
},
....Vespa のグルーピングでは、各グループ内のドキュメント群は relevancy の降順でソートされます。
そのため、max 指定をした場合は そのグループを relevancy の降順で並べた場合の上位 が選ばれます。
|
上記のように、Vespa のグルーピングでは、グループ内のドキュメントは必ず 幸い、 |
連続値に対するグルーピング
Vepsa では連続値のフィールドに対しても、分割の単位 (bucket) を定義することでグルーピングを行うことができます。
例えば、price を 2000円未満、2000円以上4000未満、4000円以上 の3つのバケットでグルーピングする場合の式は以下のようになります。
all(
group(
predefined( (1)
price, (2)
bucket(0, 2000), (3)
bucket(2000, 4000), (4)
bucket(4000, inf) (5)
)
)
each(
output(count())
)
)| 1 | predefined(field, bucket, …) でグルーピング対象のバケットを定義 |
| 2 | 対象フィールドは price |
| 3 | 0 <= price < 2000 のバケットを定義 |
| 4 | 2000 <= price < 4000 のバケットを定義 |
| 5 | 4000 <= price のバケットを定義 |
例えば、全ドキュメントに対して上記のグルーピングを組み合わせると以下のような検索クエリになります。
search/?language=ja&query=sddocname:book&select=all(group(predefined(price, bucket(0, 2000), bucket(2000, 4000), bucket(4000, inf))) each(output(count())))結果、以下のように各価格帯でのヒット件数が得られます。
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:predefined(price, bucket[0, 2000>, bucket[2000, 4000>, bucket[4000, inf>)",
"relevance": 1,
"label": "predefined(price, bucket[0, 2000>, bucket[2000, 4000>, bucket[4000, inf>)",
"children": [
{
"id": "group:long_bucket:0:2000",
"relevance": 0,
"limits": {
"from": "0",
"to": "2000"
},
"fields": {
"count()": 4
}
},
{
"id": "group:long_bucket:2000:4000",
"relevance": 0,
"limits": {
"from": "2000",
"to": "4000"
},
"fields": {
"count()": 6
}
},
{
"id": "group:long_bucket:4000:9223372036854775807",
"relevance": 0,
"limits": {
"from": "4000",
"to": "9223372036854775807"
},
"fields": {
"count()": 3
}
}
]
}
]
},
...|
|
多階層グルーピング
Vespa ではグルーピングの中でさらにグルーピングを定義する、いわゆる多階層グルーピングをサポートしています。
例えば、genres の第一ジャンルでグルーピングしたのち、さらに第二ジャンルでグルーピングする場合は以下のような式になります。
all(
group(array.at(genres, 0)) (1)
each(
output(count()) (2)
all(
group(array.at(genres, 1)) (3)
each(
output(count()) (4)
)
)
)
)| 1 | 第一ジャンル (array.at(genres, 0)) でグルーピング |
| 2 | 第一ジャンルの各グループについてヒット数を出力 |
| 3 | 第二ジャンル (array.at(genres, 1)) でさらにグルーピング |
| 4 | 第二ジャンルの各グループについてヒット数を出力 |
|
新しい
|
これを例えば query=title:入門 と組み合わせると、検索クエリは以下のようになります。
search/?language=ja&query=title:入門&select=all(group(array.at(genres, 0)) each(output(count()) all(group(array.at(genres, 1)) each(output(count())))))結果、以下のように第一ジャンルと第二ジャンルでネストしたグルーピング結果が取得されます。
{
"root": {
...
"children": [
{
"id": "group:root:0",
"relevance": 1,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:array.at(genres, 0)",
"relevance": 1,
"label": "array.at(genres, 0)",
"children": [
{
"id": "group:string:コンピュータ",
"relevance": 0.15974580091895013,
"value": "コンピュータ",
"fields": {
"count()": 2
},
"children": [
{
"id": "grouplist:array.at(genres, 1)",
"relevance": 1,
"label": "array.at(genres, 1)",
"children": [
{
"id": "group:string:プログラミング",
"relevance": 0.15974580091895013,
"value": "プログラミング",
"fields": {
"count()": 1
}
},
{
"id": "group:string:検索エンジン",
"relevance": 0.15968230614070084,
"value": "検索エンジン",
"fields": {
"count()": 1
}
}
]
}
]
}
]
}
]
},
...4.3. その他の検索
Vespa ではここまでで紹介した検索以外にも、次のような機能が提供されています。
この節では、これら機能の概要について簡単に紹介します (詳細は公式ドキュメントを参照してください)。
|
WAND 検索と Predicate フィールドでは検索クエリとして YQL を用いる必要があります。 |
4.3.1. 位置検索
位置検索
では、スキーマ定義の時に position 型という緯度・経度を保持するフィールドを定義して利用します。
// schema
field latlong type position { (1)
indexing: attribute
}
// feed
"fields": {
"latlong": "N35.680;W139.737" (2)
}
// search
search/?query=yahoo&pos.ll=N35.680%3BW139.737&pos.radius=1km (3)| 1 | position 型としてフィールドを定義 |
| 2 | 北緯32.680度、東経139.737を登録 |
| 3 | 北緯32.680度、東経139.737の地点から半径1km圏内 |
上の例のように、位置検索では緯度・経度に基づく範囲検索が可能となっています。
4.3.2. WAND 検索
WAND 検索
は
Broder 等の論文
で発表された WAND (Weak AND or Weighted AND の略) と呼ばれる手法を用いた検索機能です。
WAND 検索は、イメージとして以下のようにクエリとドキュメントの各単語に重みを付け、
その内積のスコアを元に Top Nを検索するような手法です。
query : {"foo": 2, "bar": 4}
doc1 : {"foo": 0.6, "fizz": 0.1} -> 2 * 0.6 = 1.2
doc2 : {"foo": 0.3, "bar": 0.5} -> 2 * 0.3 + 4 * 0.5 = 2.6
doc3 : {"bar": 0.2, "buzz": 0.8} -> 4 * 0.2 = 0.8WAND 検索では、ドキュメントの各単語について全ドキュメント中での上限スコアを予め計算し、
それを用いて候補ドキュメントを効率的に枝刈りしていきます。
なお、WAND 検索を行う場合、対象のフィールドは weightedset として定義されている必要があります。
WAND 検索は、特に非常に多くの OR 条件があるようなクエリを扱う場合に効果的です。 典型的な例としては「ユーザの行動履歴に基いてレコメンドを行うシステム」が考えられます。 レコメンドシステムでは、ユーザが行動履歴から推定されたユーザのタグ情報と、 ドキュメントが持つタグ情報との類似度を計算して、ユーザが興味を持ちそうなドキュメントを選択します。 この類似度は2つのタグ集合 (ベクトル) の内積として表現できるため、 先程の例の "単語" を "タグ"、"重み" を "関連度" に置き換えれば実現できることがわかります。 このタグ情報は非常に種類が多くなるはずで、普通にユーザの興味タグを OR 検索すると計算コストがとても大きくなります。 それに対して、WAND 検索の場合は前述のように検索の過程で効率的に枝刈りを行うため、計算コストを劇的に抑えることができます。
|
Vespa のドキュメントでは WAND 検索として
個人的な見解としては、
WAND 検索を行うならば理論保障がしっかりしている |
4.3.3. Predicate フィールド
Predicate フィールド はドキュメント側に条件式を埋め込み、検索クエリで指定された属性値にマッチしたドキュメントを返却する機能です。 通常の検索の場合は検索クエリ側で条件式を書きますが、 Predicate フィールドではインデックス側にその構造を埋め込む、というのが特徴です。
// schema
field target type predicate { (1)
indexing: attribute
}
// feed
"fields": {
"target": "gender in [Female] and age in [20..30]" (2)
}
// query
select/?yql=select * from sources * where predicate(target, {"gender":"Female"}, {"age": 20L}) (3)| 1 | predicate 型としてフィールドを定義 |
| 2 | ドキュメントのターゲットを女性 (gender in [Female]) で20-30歳 (age in [20..30]) に設定 |
| 3 | 女性 ({"gender":"Female"}) かつ 20歳 ({"age":20L}) にマッチするドキュメントを検索 |
|
クエリ中の |
Predicate フィールドの典型的な利用例としては、広告のターゲティングが考えられます。 広告のターゲティングの場合、ドキュメントは広告本体であり、 そこに Predicate フィールドとして広告のターゲット層の条件式を指定することになります。 検索時はユーザの属性情報をクエリに指定することで、対応する広告が取得できます。
4.3.4. ストリーミング検索
ストリーミング検索
はドキュメントを grep で検索するような機能に相当します。
ストリーミング検索ではインデックス構造が通常とは異なり、転置インデックスを構築せずに生データのみを保持します。
このため、ストリーミング検索を有効にするためには、
インデックス構築時に以下のような明示的に streaming を指定する必要があります。
<content id="mycluster" version="1.0">
<documents>
<document type="mytype" mode="streaming" />|
インデックス構造が変わるため、設定を変更する場合は再インデックスが必須です。 |
ストリーミング検索では、全てのドキュメントを検索するのは非常にコストがかかるためで、
検索時に検索対象のドキュメントのブロックを指定する必要があります。
このブロックは
ドキュメントID
の TIP の中で説明した n=NUM および g=GROUP の指定が対応します。
ストリーミング検索では、以下のようにワイルドカードを用いた検索が可能です。
search/?q=*ytho*&streaming.userid=12345678ここで、streaming.userid はドキュメント ID の n=NUM に相当する番号です。
g=GRUOP と指定して登録した場合は streaming.groupname を用います。
ストリーミング検索は非常に限定的な範囲を検索するときに選択肢の一つとなります。 具体例としては、ユーザが自分自身のデータを検索するようなケース (メールとか) が考えられます。 このユースケースの場合、ユーザが参照するドキュメントは非常に限定的であり、 その配置は前述のドキュメント ID の指定で制御が可能なため、ストリーミング検索の適用できます。
5. Vespa とランキング
このセクションでは、 Vespa のランキング について見ていきます。
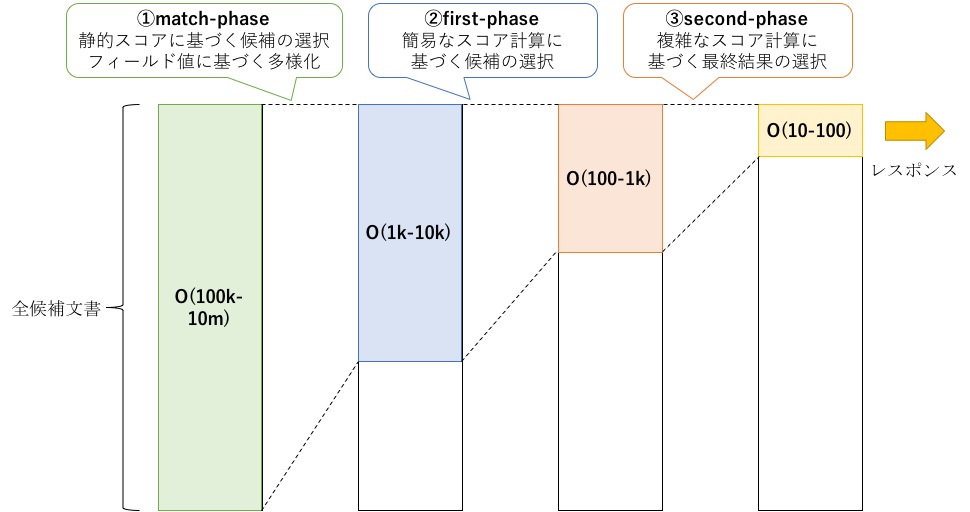
5.1. ランキングの流れ
Vespa のランキングは以下の図のように大きく3つのフェーズで構成されます。
5.1.1. match-phase
match-phase は実際のランキング計算の前に存在するフェーズで、
特定のフィールド値に基いて候補文書を選択します。
選択の基準には、例えば最終スコアと相関のあるフィールド値 (ex. クリック数とか) や、
事前にフィード時に計算した静的スコアなどが一般的に利用されます。
Vespa ではこれに加え、特定のフィールド値について候補文書を多様化 (diversity) する機能もこのフェーズで実行できます。
これは、例えば「match-phase で選択された文書には最低でも10個の異なるカテゴリの文書を含める」のように、
検索候補のバリエーションを担保する操作のことです。
|
|
5.1.2. first-phase
first-phase では計算コストの相対的に小さいスコア計算 (検索モデル) を用いて、
次段の second-phase で評価対象となる候補文書を絞り込みます。
最終的なソートは次段の second-phase が担当するため、
first-phase では 「文書群の中からいかに上位候補を網羅して選択するか (再現率、recall の最大化)」
が重要となります。
first-phase で利用するスコア計算は、
一般的には second-phase で用いるスコア計算と相関があるような式を選びます。
Vespaでは、クエリと文書との関連度をざっくり計算するヒューリスティックな軽量関数 (
nativeRank
) が提供されており、
デフォルトではそれが first-phase のスコア計算で利用されます。
なお、多くの場合、first-phase で絞り込まれる件数は 100-1000 程度のオーダとなります。
|
このように軽量モデルと重量モデルの2段階でランキングを行う手法は |
5.1.3. second-phase
second-phase では first-phase で選ばれた候補文書を再度スコア計算し、最終的な順位付けを行います。
このフェーズで選ばれた上位の文書が実際にユーザに返却されるレスポンスとなるため、
second-phase では「文書群の中からいかに真に関連する文書を選択するか (適合率、precision の最大化)」
が重要となります。
second-phase は前述の通りその精度がユーザのレスポンスに直結するため、
一般的に機械学習を用いた複雑で高精度なモデルがスコア計算で利用されます。
|
検索でよく使われるモデルとしては アンサンブル木 があげられます。 |
5.2. rank-profile
Vespa ではランキングは
searchdifinitions
の中に
rank-profile
として定義します。
例えば、チュートリアルの
sample-apps/config/ranking/searchdefinitions/book.sd
では以下のように3つのランキングが定義されています。
rank-profile basic inherits default {
first-phase {
expression: nativeRank
}
}
rank-profile price_boost inherits basic {
rank-properties {
query(bias) : 0.1
}
macro price_boost() {
expression: file:price_boost.expression
}
macro boosted_score(bias) {
expression {
(1.0 - bias) * firstPhase
+ bias * price_boost
}
}
second-phase {
expression: boosted_score(query(bias))
rerank-count: 3
}
}
rank-profile reviews_prefer inherits default {
first-phase {
expression: dotProduct(reviews, prefer)
}
}rank-profile で定義される代表的な要素として以下のようなものがあります。
| 要素 | 役割 |
|---|---|
rank-properties |
ランク計算で利用する種々のパラメタを定義します。 |
macro |
計算式を一つにまとめたマクロを定義します。 |
first-phase |
|
second-phase |
|
inherits |
他の |
|
本チュートリアルでは |
5.2.1. rank-properties
rank-properties には各種組み込み素性の設定を以下のフォーマットで指定します。
rank-properties {
<featurename>.<configuration-property>: <value>
}rank-properties で指定可能なパラメタは公式ドキュメントの以下のページに記載があります。
|
指定可能な |
チュートリアルの例では、以下のように query という検索クエリから動的に値を指定する素性について、
そのデフォルト値の定義が書かれています。
rank-properties {
query(bias) : 0.1 (1)
}| 1 | query(bias) という素性のデフォルト値を 0.1 に設定 |
5.2.2. macro
macro
ではスコア計算をまとめたマクロを定義します。
共通ロジックをマクロとして切り出して使いまわすことで、rank-profile の見通しがよくなります。
また、後述の継承機能を利用することで、ベースの rank-profile に共通ロジックのマクロをまとめておき、
継承先の rank-profile でそれらを参照する、といった使い方も可能です。
チュートリアルの例では、以下のように price_boost と boosted_score という2つのマクロが定義されています。
macro price_boost() { (1)
expression: file:price_boost.expression
}
macro boosted_score(bias) { (2)
expression {
(1.0 - bias) * firstPhase
+ bias * price_boost
}
}| 1 | 引数なしマクロとして price_boost を定義 |
| 2 | 引数ありマクロとして boosted_score(bias) を定義 |
なお、上記例の boosted_score のように、マクロには引数を定義することも可能です。
5.2.3. first-phase
first-phase
では前述の first-phase での具体的なスコア計算を定義します。
チュートリアルの例では、以下のよう expression として数式の定義がされています。
first-phase {
expression: nativeRank (1)
}| 1 | first-phase のスコアとして nativeRank を用いる。 |
なお、first-phase を明示的に指定しなかった場合、デフォルトでは nativeRank がスコア計算として利用されます。
5.2.4. second-phase
second-phase
では前述の second-phase での具体的なスコア計算を定義します。
チュートリアルの例では、以下のように first-phase とほぼ同じ見た目で定義がされています。
second-phase {
expression: boosted_score(query(bias)) (1)
rerank-count: 3 (2)
}| 1 | second-phase のスコアとして boosted_score(query(bias)) を用いる。 |
| 2 | first-phase の返却値のうち上位3件を second-phase の対象とする。 |
second-phase で指定される rerank-count は、
first-phase のスコアでソートされたドキュメントの上位何件を second-phase の評価対象とするかを指定しています。
rerank-count のデフォルト値は 100 で、100-1000 程度の値が使われる印象です (計算コストと相談)。
|
もし、
という順番となり、足りない分は |
5.2.5. inherits
inherits は rank-profile を定義するときに指定する要素で、別の rank-profile からの継承を指定します。
チュートリアルの例では、以下のように継承が定義されています。
rank-profile basic inherits default { (1)
...
}
rank-profile price_boost inherits basic { (2)
...
}
rank-profile reviews_prefer inherits default { (3)
...
}| 1 | default を継承して basic を定義 |
| 2 | basic を継承して price_boost を定義 |
| 3 | default を継承して reviews_prefer を定義 |
上記例で出てくる default は Vespa がデフォルトで定義している rank-profile です。
|
Vespa の継承はいわゆる 最終的な 上記例のように、 |
5.3. ランク式
Vespaでは上記例の中でもでてきたように、 スコア式を数式 (ランク式) として記述できます。
5.3.1. rank-profile上での書き方
rank-profile 上では、expression というキーの後に数式を書きます。
書き方としては以下の3種類があります。
expression: 1+2 (1)
expression { (2)
1
+
2
}
expression: file: myfunc.expression (3)| 1 | ワンライナーでランク式を記述 |
| 2 | 複数行に分けてランク式を記述 |
| 3 | ランク式を外部ファイル (myfunc.expression) に書いて読み込み |
3つ目の外部ファイルを利用する場合、myfunc.expression は以下のように searchdefitions の階層に配置する必要があります。
myconfig/
`- searchdefinitions/
|- myindex.sd
|- myfunc.expression
`- ...
$ cat myconfig/searchdefinitions/myfunc.expression
1+2|
Vespa は外部ファイルも |
5.3.2. ランク式の記法
Vespa では、 Ranking Expressions にあるように、
-
四則演算 (
+,-,*,/) -
数学関数 (
cos,sin,tan, etc…) -
条件式 (
if(cond, true, false))
といった記法を使うことができます。
四則演算
以下のように通常のプログラミングのように記述します。
a + b - c * d / (e + f)|
剰余算は |
数学関数
Vespa のランク式では以下のような数学関数が利用できます (意味は通常のプログラミングでの関数と同じです)。
| 関数 | 動作 |
|---|---|
cosh(x) |
|
sinh(x) |
|
tanh(x) |
|
cos(x) |
|
sin(x) |
|
tan(x) |
|
acos(x) |
|
asin(x) |
|
atan2(y, x) |
|
atan(x) |
|
exp(x) |
|
ldexp(x, exp) |
|
log10(x) |
|
log(x) |
|
pow(x, y) |
|
sqrt(x) |
|
ceil(x) |
|
fabs(x) |
|
floor(x) |
|
isNan(x) |
|
fmod(x, y) |
|
min(x, y) |
|
max(x, y) |
|
条件式
Vespa のランク式では条件式は以下のような3項演算子として記述します。
if (expression1 operator expression2, trueExpression, falseExpression)第一項は条件式が入り、以下のような条件演算子が使えます。
| 演算子 | 動作 |
|---|---|
x <= y |
|
x < y |
|
x == y |
|
x ~= y |
|
x >= y |
|
x > y |
|
x in [a,b,c,…] |
|
|
|
第二項は条件式が true の時に実行されるランク式が、
第三項は条件式が false の時に実行されるランク式がそれぞれ入ります。
5.3.3. 組み込み素性
Vespa では以下のドキュメントのようにランク式を記述するときに役に立つ様々な組み込み素性 (ランク素性) が定義されています。
ここでは代表的なものをピックアップして簡単に紹介します。
nativeRank
nativeRank は Vespa の中でよく用いられるヒューリスティックなスコア計算式で、
後述の nativeFieldMatch、nativeProximity、および nativeAttributeMatch の加重平均として計算されます (
数式
)。
加重平均で用いる各素性の重みは rank-properties で調整可能で、デフォルト値は以下のようになっています。
rank-properties {
nativeRank.fieldMatchWeight: 100.0
natievRank.proximityWeight: 25.0
nativeRank.attributeMatchWeight: 100.0
}なお、nativeRank はデフォルトでは検索クエリで指定された全てのフィールドが評価対象となります。
特定のフィールドに限定した結果が欲しい場合は、
nativeRank(title, desc) のように引数に対象のフィールド名を列挙します。
nativeFieldMatch
nativeFieldMatch は、
トークナイズされるフィールド (indexing: index) を対象に、
検索クエリとフィールドのマッチ具合を計算するヒューリスティック手法です (
数式
)。
nativeFieldMatch は以下の2つのポイントでスコアが決まります。
-
検索ワードがフィールド上でどれだけ先頭に出現したか (
firstOccBoost) -
検索ワードがフィールド上でどれだけ多く出現したか (
numOccBoost)
最終スコアはこれら2つのスコアの加重平均を 0.0-1.0 に正規化した値となります。
デフォルトでは2つのスコアは単純に同じ比重 (0.5) で結合されます。
rank-properties {
nativeFieldMatch.firstOccurrenceImportance: 0.5
}なお、nativeFieldMatch も nativeRank と同じように、引数にフィールド名を指定できます。
|
Vespa ではスコア計算時に各単語 (
|
nativeProximity
nativeProximity は、
トークナイズされるフィールド (indexing: index) を対象に、
検索クエリでの単語群がどの程度隣接して出現するかを計算するヒューリスティック手法です (
数式
)。
nativeProximity では以下の2つのポイントでスコアが決まります。
-
検索ワードのセットがフィールド上で順方向にどれだけ隣接していたか
-
検索ワードのセットがフィールド上で逆方向にどれだけ隣接していたか
基本的に順方向で隣接していた方がスコアが高くなるように設計されています。
最終スコアは2つのスコアの加重平均を 0.0-1.0 に正規化した値となります。
デフォルトでは2つのスコアは単純に同じ比重 (0.5) で結合されます。
また、検索クエリの単語群のうち、どこまでの範囲のペアを評価対象にするか
(window 幅、 slidingWindowSize)
も rank-properties で指定ができます。
デフォルトは 4 で、例えば a b c d e という5単語場合、window 幅が 4 を超える a e のペアは評価対象外となります。
rank-properties {
nativeProximity.proximityImportance: 0.5
nativeProximity.slidingWindowSize: 4
}なお、nativeProximity も nativeRank と同じように、引数にフィールド名を指定できます。
|
単語ペアの重みは前述の |
nativeAttributeMatch
nativeAttributeMatch は
トークナイズされないフィールド (indexing: attribute) を対象に、
検索クエリとフィールドのマッチ具合を計算するヒューリスティック手法です (
数式
)。
nativeAttributeMatch のスコア計算では、単純に対象の単語のフィールドでの出現数がスコアに影響します。
出現数の算出方法は、対象フィールドのタイプによって以下のように変化します。
-
weightedset : マッチした単語の重みの合計値
-
array : マッチした単語の数
-
single : マッチした単語の数 (つまり、
0か1)
最終的なスコアは単語に重みを元に 0.0-1.0 に正規化されます。
なお、nativeAttributeMatch も nativeRank と同じように、引数にフィールド名を指定できます。
|
|
attribute
attribute は
フィールド値を参照するときに利用する素性です。
名前のように、attribute で指定できるフィールドは indexing: attribute と指定されたものに限定されます。
attribute ではフィールドの型によって以下のような呼び出し方ができます。
| 素性 | 意味 |
|---|---|
attribute(name) |
|
attribute(name, n) |
|
attribute(name, key).weight |
|
attribute(name, key).contains |
|
attribute(name).count |
|
|
|
fieldMatch
fieldMatch は
一つのトークナイズされたフィールド (indexing: index) を対象に、
segment match
と呼ばれるマッチング手法によって、クエリとフィールドのマッチ具合を評価する素性です。
|
|
segment match では、
公式ドキュメントの図
のようにフィールド全体から検索クエリの単語群が最も密に集まったところ (セグメント) を探索します。
{kind=link}
fieldMatch では以下のような要素がスコア計算に加味されます。
-
各セグメントがどれだけ隣接しているか
-
同一セグメント内でどれだけ単語が密に集まっているか
-
選択されたセグメントの中での単語の出現順がクエリでの順番と揃っているか
-
フィールド全体で検索クエリの単語がどれだけ多く出現したか
-
検索クエリの単語がフィールド全体の何割をカバーしたか
-
検索クエリの単語のうち何割がフィールドに出現したか
また、fieldMatch では評価の過程で計算された以下のような中間データも参照できます
(以下は一部の例で、これ以外にもあります)。
| 素性 | 意味 |
|---|---|
fieldMatch(name) |
|
fieldMatch(name).proximity |
セグメント内での単語の隣接度合いのスコア。 |
fieldMatch(name).completeness |
検索単語のクエリ及びフィールドのカバー率のスコア。 |
fieldMatch(name).orderness |
検索クエリと実際のフィールド上での出現順のスコア。 |
fieldMatch(name).relatedness |
検索クエリがどれだけ同一のセグメントに出現したかのスコア。 |
fieldMatch(name).earliness |
検索クエリがどれだけ先頭の方に出現したかのスコア。 |
fieldMatch(name).segmentProximity |
異なるセグメントがどれだけ隣接しているかのスコア。 |
fieldMatch(name).occurrence |
検索クエリの単語の出現数に基づくスコア。 |
fieldMatch(name).weight |
フィールド中に出現した検索単語の |
fieldMatch(name).significance |
フィールド中に出現した検索単語の |
fieldMatch(name).matches |
フィールド中に出現した検索単語の出現数 (種類数かも)。 |
fieldMatch はその動作を制御する様々なパラメタも定義されています。
詳しくは
Rank feature configuration
を参照してください。
|
|
|
|
attributeMatch
attributeMatch
は一つのトークナイズされていないフィールド (indexing: attribute) を対象に、
検索クエリの単語とフィールドの値がどれだけ一致したかを評価する素性です。
|
|
attributeMatch は fieldMatch と名称が似ていますが、
こちらは単純にマッチした単語の全体に対するカバー率のみがスコア計算に加味されます。
また、attributeMatch では以下のような中間データも参照できます
(以下は一部の例で、これ以外にもあります)。
| 素性 | 意味 |
|---|---|
attributeMatch(name) |
|
attributeMatch(name).completeness |
検索単語のクエリおよびフィールドのカバー率のスコア。 |
attributeMatch(name).weight |
フィールド中に出現した検索単語の |
attributeMatch(name).significance |
フィールド中に出現した検索単語の |
attributeMatch(name).matches |
フィールド中に出現した検索単語の出現数 (種類数かも)。 |
attributeMatch(name).totalWeight |
|
attributeMatch(name).averageWeight |
|
query
query
は検索クエリから動的に値を指定するときに使用する素性です。
query を利用する場合は、rank-properties に指定がない場合のデフォルト値を一緒に定義します。
rank-properties {
query(gender): male
query(age) : 30
}検索クエリからは、以下の例のように ranking.features.featurename [rankfeature.featurename] というパラメタで指定します。
search?language=ja&query=foo&rankfeature.query(gender)=female&rankfeature.query(age)=25dotProduct
dotProduct
は weightedest なフィールドと内積を計算するときに利用する素性です。
dotProduct は以下のように第1引数に対象のフィールドを、第2引数に検索クエリから与えるベクトルの名称を指定します。
dotProduct(reviews, prefer) (1) (2)| 1 | weightedset な reviews フィールドに対して適用 |
| 2 | prefer というベクトルとの内積を計算 |
検索クエリでは以下のように
ranking.properties.propertyname [rankproperty.propertyname]
というパラメタで指定します。値のベクトルは json 形式で指定します。
search?language=ja&query=入門&rankproperty.dotProduct.prefer={quality:0.2, readability:0.5, cost:0.3}|
似たような素性として |
|
|
5.4. ランキングと検索
Vespaでは検索クエリの
ranking.profile [ranking]
というオプションを用いて、実際に適用する rank-profile を指定します。
実際にチュートリアルデータを用いてその動作について見ていきます。
|
Vespaではデフォルトで利用できる |
Vespaへのデプロイ で説明した手順に従って新しい設定をVespaにデプロイします。
|
事前に チュートリアル環境の構築 の手順に従ってVespaを起動して、 サンプルデータの登録 まで完了している必要があります。 |
$ sudo docker-compose exec vespa1 /bin/bash (1)
[root@vespa1 /]# vespa-deploy prepare /vespa-sample-apps/config/ranking/ (2)
Uploading application '/vespa-sample-apps/config/ranking/' using http://vespa1:19071/application/v2/tenant/default/session?name=ranking
Session 3 for tenant 'default' created.
Preparing session 3 using http://vespa1:19071/application/v2/tenant/default/session/3/prepared
Session 3 for tenant 'default' prepared.
[root@vespa1 /]# vespa-deploy activate (3)
Activating session 3 using http://vespa1:19071/application/v2/tenant/default/session/3/active
Session 3 for tenant 'default' activated.
Checksum: 5d15aa7ef48459f19057915f1f8096dc
Timestamp: 1519187200940
Generation: 3| 1 | vespa1 のdockerコンテナにログイン |
| 2 | /vespa-sample-apps/config/ranking/ をVespaにアップロード |
| 3 | 最新の設定をVespaに反映 |
5.4.1. チュートリアルのモデル
ランキングを含む Vespa の設定は
sample-apps/config/ranking に配置されています。
serchdefinitions/book.sd では以下のような3つのプロファイルが定義されています。
basic
継承の例のために切り出した基底の rank-profile で、後述の price_boost のベースとなっています。
中身は default と同じで、first-phase に nativeRank を指定しただけです。
price_boost
first-phase で得られた結果のうち、上位3位の結果を price の値でブーストしてリランキングする rank-profile です。
rank-profile price_boost inherits basic {
rank-properties {
query(bias) : 0.1
}
macro price_boost() {
expression: file:price_boost.expression
}
macro boosted_score(bias) {
expression {
(1.0 - bias) * firstPhase
+ bias * price_boost
}
}
second-phase {
expression: boosted_score(query(bias))
rerank-count: 3
}
}price-boost では、boosted_score(bias) マクロの中で
first-phase のスコア (firstPhase) と価格ブースト値の bias に基づく加重平均を計算しています。
bias の値は query 素性として検索時に変更できるようにしています。
価格ブースト値は price_boost() マクロで定義されており、実際の定義は以下のように外部ファイルに記載されています。
$ cat sample-apps/config/ranking/searchdefinitions/price_boost.expression
1.0 - tanh(log10(attribute(price)/1000))|
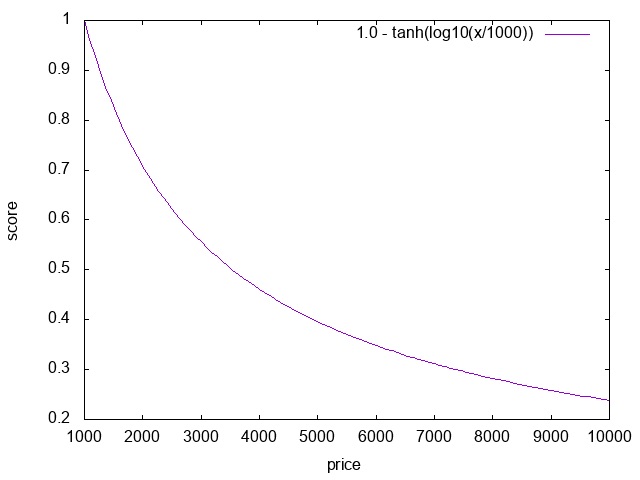
|
reviews_prefer
ユーザの嗜好とドキュメントのレビュースコアの内積値を用いてリランキングをする rank-profile です。
rank-profile reviews_prefer inherits default {
first-phase {
expression: dotProduct(reviews, prefer)
}
}このプロファイルは、ユーザの嗜好を rankproperty.dotProduct.perfer=JSON として検索時に与えることを想定しており、
簡単なパーソナライズのような例となっています。
5.4.2. 検索結果の比較
まず、ベース設定 (ranking=basic) で検索をした場合、検索結果の上位3件は以下のようになります。
search/?language=ja&query=入門&count=3&ranking=basic
{
"root": {
"id": "toplevel",
"relevance": 1,
"fields": {
"totalCount": 3
},
"coverage": {
"coverage": 100,
"documents": 13,
"full": true,
"nodes": 0,
"results": 1,
"resultsFull": 1
},
"children": [
{
"id": "id:book:book::python_intro",
"relevance": 0.07987290045947507,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Python本格入門",
"desc": "今話題のPythonの使い方をわかりやすく説明します",
"price": 2000,
"page": 450,
"genres": [
"コンピュータ",
"プログラミング",
"Python"
],
"reviews": [
{
"item": "readability",
"weight": 80
},
{
"item": "cost",
"weight": 70
},
{
"item": "quality",
"weight": 50
}
],
"documentid": "id:book:book::python_intro"
}
},
{
"id": "id:book:book::vespa_intro",
"relevance": 0.07984115307035042,
"source": "book",
"fields": {
"sddocname": "book",
"title": "ゼロから始めるVespa入門",
"desc": "話題のOSS検索エンジン、Vespaの使い方を初心者にもわかりやすく解説します",
"price": 1500,
"page": 200,
"genres": [
"コンピュータ",
"検索エンジン",
"Vespa"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 80
},
{
"item": "quality",
"weight": 40
}
],
"documentid": "id:book:book::vespa_intro"
}
},
{
"id": "id:book:book::java_intro",
"relevance": 0.06998285745781,
"source": "book",
"fields": {
"sddocname": "book",
"title": "サルでも分かるJava言語",
"desc": "Java超初心者におすすめのJava言語の入門書です",
"price": 1000,
"page": 150,
"genres": [
"コンピュータ",
"プログラミング",
"Java"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 90
},
{
"item": "quality",
"weight": 30
}
],
"documentid": "id:book:book::java_intro"
}
}
]
}
}これを price_boost をランキングに指定して検索すると、以下のように価格の安いものが上位にくるように検索結果が変化します。
search/?language=ja&query=入門&count=3&ranking=price_boost
{
"root": {
"id": "toplevel",
"relevance": 1,
"fields": {
"totalCount": 3
},
"coverage": {
"coverage": 100,
"documents": 13,
"full": true,
"nodes": 0,
"results": 1,
"resultsFull": 1
},
"children": [
{
"id": "id:book:book::java_intro",
"relevance": 0.162984571712029,
"source": "book",
"fields": {
"sddocname": "book",
"title": "サルでも分かるJava言語",
"desc": "Java超初心者におすすめのJava言語の入門書です",
"price": 1000,
"page": 150,
"genres": [
"コンピュータ",
"プログラミング",
"Java"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 90
},
{
"item": "quality",
"weight": 30
}
],
"documentid": "id:book:book::java_intro"
}
},
{
"id": "id:book:book::vespa_intro",
"relevance": 0.1544276910372906,
"source": "book",
"fields": {
"sddocname": "book",
"title": "ゼロから始めるVespa入門",
"desc": "話題のOSS検索エンジン、Vespaの使い方を初心者にもわかりやすく解説します",
"price": 1500,
"page": 200,
"genres": [
"コンピュータ",
"検索エンジン",
"Vespa"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 80
},
{
"item": "quality",
"weight": 40
}
],
"documentid": "id:book:book::vespa_intro"
}
},
{
"id": "id:book:book::python_intro",
"relevance": 0.14266011876532916,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Python本格入門",
"desc": "今話題のPythonの使い方をわかりやすく説明します",
"price": 2000,
"page": 450,
"genres": [
"コンピュータ",
"プログラミング",
"Python"
],
"reviews": [
{
"item": "readability",
"weight": 80
},
{
"item": "cost",
"weight": 70
},
{
"item": "quality",
"weight": 50
}
],
"documentid": "id:book:book::python_intro"
}
}
]
}
}1件目のスコア (relevance) は 0.162984571712029 となっていますが、
これは以下のように定義した式で計算した結果になっていることがわかります。
price_boost() = 1.0 - tanh(log10(1000/1000))
= 1.0
query(bias) = 0.1 (default)
boosted_score(query(bias)) = boosted_score(0.1)
= (1.0 - 0.1) * 0.06998285745781 + 0.1 * 1.0
= 0.162984571712029例えば、以下のクエリのように query(bias) = 0.0 とすると、価格ブーストの値が無視され、
初めの結果と同じになることが確認できます。
search/?language=ja&query=入門&count=3&ranking=price_boost&rankfeature.query(bias)=0.0
(`ranking=basic` の場合と同じ検索結果)次に、以下のようにユーザの嗜好を {quality:0.2, readability:0.5, cost:0.3} として、
reviews_prefer で検索すると以下のような結果が得られます。
search/?language=ja&query=入門&count=3&ranking=reviews_prefer&rankproperty.dotProduct.prefer={quality:0.2, readability:0.5, cost:0.3}
{
"root": {
"id": "toplevel",
"relevance": 1,
"fields": {
"totalCount": 3
},
"coverage": {
"coverage": 100,
"documents": 13,
"full": true,
"nodes": 0,
"results": 1,
"resultsFull": 1
},
"children": [
{
"id": "id:book:book::java_intro",
"relevance": 78,
"source": "book",
"fields": {
"sddocname": "book",
"title": "サルでも分かるJava言語",
"desc": "Java超初心者におすすめのJava言語の入門書です",
"price": 1000,
"page": 150,
"genres": [
"コンピュータ",
"プログラミング",
"Java"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 90
},
{
"item": "quality",
"weight": 30
}
],
"documentid": "id:book:book::java_intro"
}
},
{
"id": "id:book:book::vespa_intro",
"relevance": 77,
"source": "book",
"fields": {
"sddocname": "book",
"title": "ゼロから始めるVespa入門",
"desc": "話題のOSS検索エンジン、Vespaの使い方を初心者にもわかりやすく解説します",
"price": 1500,
"page": 200,
"genres": [
"コンピュータ",
"検索エンジン",
"Vespa"
],
"reviews": [
{
"item": "readability",
"weight": 90
},
{
"item": "cost",
"weight": 80
},
{
"item": "quality",
"weight": 40
}
],
"documentid": "id:book:book::vespa_intro"
}
},
{
"id": "id:book:book::python_intro",
"relevance": 71,
"source": "book",
"fields": {
"sddocname": "book",
"title": "Python本格入門",
"desc": "今話題のPythonの使い方をわかりやすく説明します",
"price": 2000,
"page": 450,
"genres": [
"コンピュータ",
"プログラミング",
"Python"
],
"reviews": [
{
"item": "readability",
"weight": 80
},
{
"item": "cost",
"weight": 70
},
{
"item": "quality",
"weight": 50
}
],
"documentid": "id:book:book::python_intro"
}
}
]
}
}この例の場合、トップのドキュメントのスコア (relevance) は以下のように reviews の内積となっていることがわかります。
dotProduct(reivews, prefer) = {quality: 30, readability: 90, cost: 90}
* {quality:0.2, readability:0.5, cost:0.3}
= 30 * 0.2 + 90 * 0.5 + 90 * 0.3
= 6 + 45 + 27
= 785.5. その他のトピック
5.5.1. 素性値のダンプ
検索の精度改善を行う場合、 実際にユーザから得られたフィードバック (ex. クリック) と検索結果に表示されたドキュメントの情報を組み合わせて訓練データを作り、 そこから機械学習を用いて新しいランキングモデルを学習する、 といったサイクルを回すのが一般的です。 このとき、検索結果のドキュメントについて、モデルで利用する素性が実際にどのような値であったかをログに残す必要があります。
Vespa では、検索結果のレスポンスに素性の計算結果を付与する機能として rank-features と summary-features という2つが提供されています。
rank-features
rank-features は素性のフルダンプを行う時に利用する機能です。検索クエリに以下のように
ranking.listFeatures [rankfeatures]
を指定すると有効になります。
search/?language=ja&query=入門&count=3&ranking=price_boost&rankfeatures=true上記クエリで検索をすると、レスポンスの各ドキュメントに rankfeatures という要素が新たに追加され、
そこに Vespa で利用可能な全ての素性のダンプ情報が出力されます。
"rankfeatures": {
"attributeMatch(genres)": 0,
"attributeMatch(genres).averageWeight": 0,
"attributeMatch(genres).completeness": 0,
"attributeMatch(genres).fieldCompleteness": 0,
"attributeMatch(genres).importance": 0,
"attributeMatch(genres).matches": 0,
...
}マクロ定義のような自分で定義した素性を追加で出力したい場合は、
以下のように rank-profile に rank-features という項目で出力したい素性の名前を列挙します。
rank-features {
rankingExpression(price_boost)
}上記のように定義すると、rankfeatures の出力に上記の項目が追加されます。
"rankfeatures": {
...
rankingExpression(price_boost)": 1,
...
}|
また、引数付きマクロについては指定できないようで、 もし実際に検索で使った値をダンプしたい場合は引数なしマクロでくくるなどの工夫が必要です。 |
|
|
|
|
summary-features
summary-features は rank-features と同じようにレスポンスに素性の値を付与する機能ですが、
こちらは指定された素性のみをレスポンスに付与する機能となります。
summary-features は rank-profile に summaryfeatures という要素を追加することで有効になります。
summary-features {
nativeRank
query(bias)
rankingExpression(price_boost)
}summaryfeatures が定義された rank-profile を指定して検索を行うと、
以下のような項目がレスポンスに追加されます。
"summaryfeatures": {
"nativeRank": 0.06998285745781,
"query(bias)": 0.1,
"rankingExpression(price_boost)": 1,
"vespa.summaryFeatures.cached": 0
},5.5.2. テンソルを用いたスコア計算
Vespa ではスコア計算の方法の一つとしてテンソル (ex. 行列) を用いた演算をサポートしています。 テンソル演算はより複雑なランキングモデルを用いるときに必要となる概念で、 代表的なユースケースとして ディープラーニング を用いたモデルがあげられます。 ここでは Vespa でのテンソル機能の概要について紹介します。
|
テンソルに関するドキュメントとして以下があります。 |
Vespa では、テンソルは以下のようなフォーマットで表現します。
{ {x:0, y:0}:5.0, {x:1, y:1}:7.0 }x と y はテンソルの次元を表す識別子で、上の例は具体的には以下のような行列を表現しています。
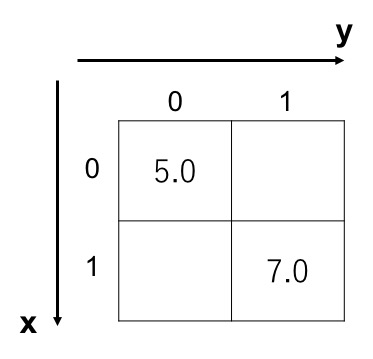
フィールド型としてテンソルを定義するときは、この次元の識別子を用いて以下のように定義します。
field sparse_tensor type tensor(x{}, y{}) { (1)
indexing: attribute | summary
attribute: tensor(x{}, y{})
}
field dense_tensor type tensor(x[], y[]) { (2)
indexing: attribute | summary
attribute: tensor(x[], y[])
}| 1 | 疎行列としてテンソルを定義 |
| 2 | 密行列としてテンソルを定義 |
|
次元の識別子は任意の名前を使用できます。
そのため、例えば |
Vespa のテンソル演算は大きくわけて以下の5つの基本操作によって構成されます。
|
公式ドキュメント
では基本操作として |
map
map は map(tensor, f(x)(expr)) のように2つの引数をとり、
第1引数で与えられたテンソルの各要素に対して、第2引数のラムダ式で与えられた操作を適用する、という動作をします。
例えば、行列の各要素を2倍するような操作は map を用いて以下のように記述します。
t = {{x:0,y:0}: 3.0, {x:0,y:1}: 4.0, {x:1,y:0}: 5.0, {x:1,y:1}: 6.0}
map(t, f(x)(x * 2)) = {{x:0,y:0}: 6.0, {x:0,y:1}: 8.0, {x:1,y:0}: 10.0, {x:1,y:1}: 12.0}reduce
reduce は reduce(tensor, aggregator, dim1, dim2, …) のような引数をとり、
第1引数で与えられたテンソルについて、第2引数で与えられた aggregator を第3引数以降で与えられた成分方向に対して適用する、
という動作をします (第3引数以降がない場合は全要素に対して適用)。
例えば、先程の x と y の2つの次元を持つ行列に対して、 x 方向に総和を取ったベクトルを得る場合、
以下のような式となります。
t = {{x:0,y:0}: 3.0, {x:0,y:1}: 4.0, {x:1,y:0}: 5.0, {x:1,y:1}: 6.0}
reduce(t, sum, x) = {{y:0}: 8.0, {y:1}: 10.0}join
join は join(tensor1, tensor2, f(x,y)(expr)) のように3つの引数を取り、
第1引数と第2引数で与えられた2つのテンソルを、第3引数のラムダ式に基いて結合する、という動作をします。
例えば、同一次元数の2つの行列に対して join(matrix1, matrix2, f(x,y)(x * y)) とすると、
これは
アダマール積
を計算することを意味します。
reduce は2つのテンソルがベクトルと行列のように次元数が異なる場合でも動作します。
例えばベクトルと行列に対して join を適用すると、
以下の例のようにベクトル側の不足している次元がワイルドカードとして扱われたような動作をします。
t1 = {{x:0}: 1.0, {x:1}: 2.0}
t2 = {{x:0,y:0}: 3.0, {x:0,y:1}: 4.0, {x:1,y:0}: 5.0, {x:1,y:1}: 6.0}
join(t1, t2, f(x,y)(x * y)) = {{x:0,y:0}: 3.0, {x:0,y:1}: 4.0, {x:1,y:0}: 10.0, {x:1,y:1}: 12.0}tensor
tensor は tensor(tensor-type-spec)(expr) のような形式で利用され、
tensor-type-spec で指定された型のテンソルを、expr で指定された式に基いて初期化した新しいテンソルを生成する、という動作をします。
expr は具体的には各次元のインデックス番号を引数とした式を記述し、例えば以下のような使い方をします。
tensor(x[3])(x) = {{x:0}: 0.0, {x:1}: 1.0, {x:2}: 2.0}
tensor(x[2],y[2])(x == y) = {{x:0,y:0}: 1.0, {x:0,y:1}: 0.0, {x:1,y:0}: 0.0, {x:1,y:1}: 1.0}concat
concat は concat(tensor1, tensor2, dim) のように3つの引数を取り、
第1引数と第2引数で与えられた2つのテンソルを、第3引数の次元方向に結合する、という動作をします。
イメージとしては第3引数の次元方向に2つのテンソルを並べる感じで、例えばベクトル同士の場合は以下のような結果となります。
t1 = {{x:0}: 0.0, {x:1}: 1.0}
t2 = {{x:0}: 2.0, {x:1}: 3.0}
concat(t1,t2,x) = {{x:0}: 0.0, {x:1}: 1.0}, {x:2}: 2.0, {x:3}: 3.0}}
Vespa ではこれら基本操作に加え、sum、relu、sigmoid、softmax といった典型的な演算が拡張操作として定義されています。
拡張操作の詳細は
Tensor Evaluation Reference
を参照してください (これら拡張操作は全て前述の基本操作を組み合わせで表現できます)。
実際の例として、以下のような単純な3層ニューラルネットワークを考えてみます。
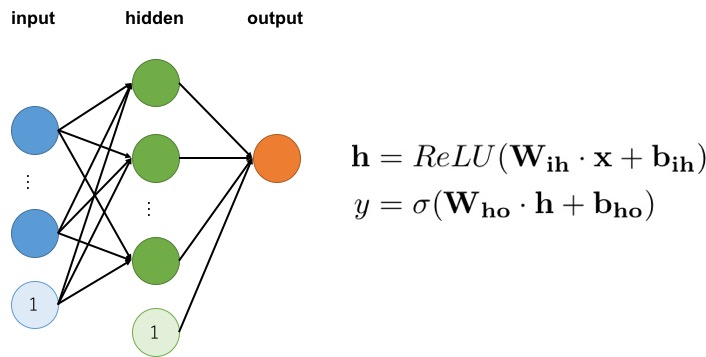
Vespa の拡張操作も組み合わせると、上記ニューラルネットワークの計算は以下のような雰囲気のランク式で記述できます。
macro h() {
expression: relu( sum(x * constant(W_ih), input) + constant(b_ih) )
}
macro y() {
expression: sigmoid( sum(h * constant(W_ho), hidden) + constant(b_ho) )
}このように、Vespa ではニューラルネットワークを用いたランク式も非常に直感的に記述できます。
|
上記ランク式では 上記例は、具体的には Vespa の公式チュートリアルを元に記述しています。 実際の完全な設定については、以下の公式チュートリアルを参照してください。 |
6. Vespa とクラスタリング
このセクションでは、複数ノードを用いて Vespa をクラスタリングする方法について見ていきます。
6.1. クラスタの構築
本チュートリアルでは、実際に3つのノードを用いた Vespa クラスタを構築します。
対応する設定は
sample-apps/config/cluster
にあります。
6.1.1. チュートリアルでの構成
構築する Vespa クラスタの構成を図にすると以下のようになります。
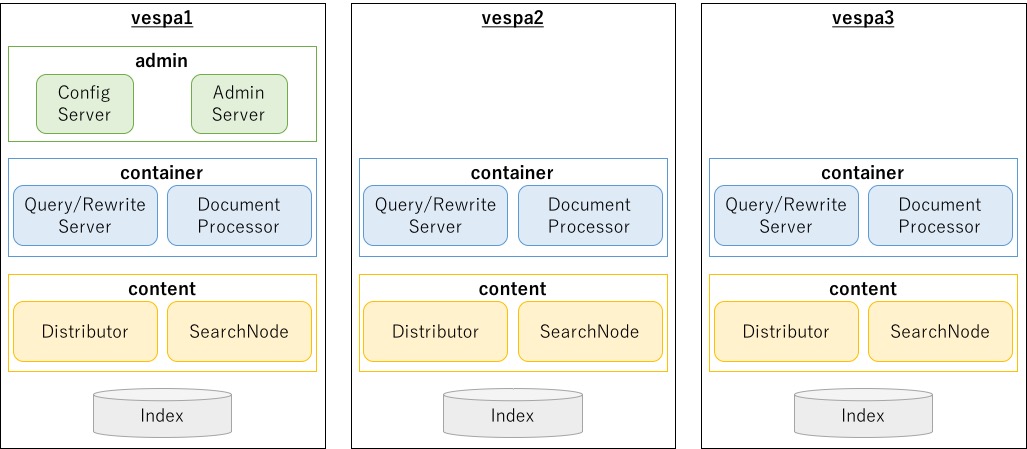
|
上図は役割軸でコンポーネントをざっくり書いたもので、ブロックと実際のプロセスが対応しているわけではない点に注意してください。 なお、実際にどのノードで何のプロセスが起動するかは Files, processes and ports にまとめられています。 |
Vespa クラスタの構築で修正が必要となるのは hosts.xml と services.xml の2つです。
hosts.xml
hosts.xml の具体的な中身は以下のようになります。
<?xml version="1.0" encoding="utf-8" ?>
<hosts>
<host name="vespa1">
<alias>node1</alias>
</host>
<host name="vespa2"> (1)
<alias>node2</alias>
</host>
<host name="vespa3"> (2)
<alias>node3</alias>
</host>
</hosts>| 1 | vespa2 のホストを追加 |
| 2 | vespa3 のホストを追加 |
Vespa の設定 で用いたシングル構成と比べて、指定されているホスト名が増えています。
services.xml
services.xml の具体的な中身は以下のようになります。
<?xml version="1.0" encoding="utf-8" ?>
<services version="1.0">
<admin version="2.0">
<adminserver hostalias="node1"/>
<configservers>
<configserver hostalias="node1"/>
</configservers>
<logserver hostalias="node1"/>
<slobroks>
<slobrok hostalias="node1"/>
</slobroks>
</admin>
<container id="container" version="1.0">
<component id="jp.co.yahoo.vespa.language.lib.kuromoji.KuromojiLinguistics"
bundle="kuromoji-linguistics">
<config name="language.lib.kuromoji.kuromoji">
<mode>search</mode>
<ignore_case>true</ignore_case>
</config>
</component>
<document-api/>
<document-processing/>
<search/>
<nodes>
<node hostalias="node1"/>
<node hostalias="node2"/>
<node hostalias="node3"/>
</nodes>
</container>
<content id="book" version="1.0">
<redundancy>2</redundancy> (1)
<documents>
<document type="book" mode="index"/>
<document-processing cluster="container"/>
</documents>
<nodes>
<node hostalias="node1" distribution-key="0"/>
<node hostalias="node2" distribution-key="1"/> (2)
<node hostalias="node3" distribution-key="2"/> (3)
</nodes>
</content>
</services>| 1 | ドキュメントの冗長数を 2 に変更 |
| 2 | vespa2 のホストを追加 |
| 3 | vespa3 のホストを追加 |
こちらもシングル構成に比べて、container と content の nodes セクションの定義が増えていることがわかります。
今回は3つのノードで同じ設定を利用するため、定義の追加はこれだけで OK です。
また、それに加えて、クラスタ設定ではドキュメントの冗長数を 1 から 2 に増やしています。
|
content
で述べたように、 |
6.1.2. クラスタ設定の反映
|
すでにシングル構成での Vespa が起動して、データまで投入されていることを前提としています。 |
シングル構成では、vespa1 のノードに13件のドキュメントが登録されているという状態でした。
チュートリアルで用意している utils/vespa_cluster_status を以下のように実行すると、
vespa1 (node=0) に13件のドキュメントがいることが確認できます。
$ utils/vespa_cluster_status -t storage book
=== status of storage ===
| node | status | bucket-count | uniq-doc-count | uniq-doc-size |
|------|-------------|--------------|----------------|---------------|
| 0 | up | 13 | 13 | 9008 ||
|
次に、以下のコマンドでクラスタの設定を Vespa にデプロイします。
$ sudo docker-compose exec vespa1 /bin/bash (1)
[root@vespa1 /]# vespa-deploy prepare /vespa-sample-apps/config/cluster/ (2)
Uploading application '/vespa-sample-apps/config/cluster/' using http://vespa1:19071/application/v2/tenant/default/session?name=cluster
Session 4 for tenant 'default' created.
Preparing session 4 using http://vespa1:19071/application/v2/tenant/default/session/4/prepared
WARNING: Host named 'vespa2' may not receive any config since it does not match its canonical hostname: vespa2.vespatutorial_vespa-nw
WARNING: Host named 'vespa3' may not receive any config since it does not match its canonical hostname: vespa3.vespatutorial_vespa-nw
Session 4 for tenant 'default' prepared.
[root@vespa1 /]# vespa-deploy activate (3)
Activating session 4 using http://vespa1:19071/application/v2/tenant/default/session/4/active
Session 4 for tenant 'default' activated.
Checksum: c170db03dc38f7f53d9b98aa89d782de
Timestamp: 1519282647370
Generation: 4| 1 | vespa1 の Docker コンテナにログイン |
| 2 | /vespa-sample-apps/config/cluster/ を Vespa にアップロード |
| 3 | 最新の設定を Vespa に反映 |
|
チュートリアルでは |
チュートリアル付属の utils/vespa_status を実行すると、
vespa2 と vepsa3 も OK になっていることがわかります。
$ utils/vespa_status
configuration server ... [ OK ]
application server (vespa1) ... [ OK ]
application server (vespa2) ... [ OK ]
application server (vespa3) ... [ OK ]また、先程の utils/vespa_cluster_status を実行すると、
ドキュメントが3つのノードに分散され、
さらに冗長数が 2 になるようにコピーが行われている (総数が26件になっている) ことが確認できます。
$ utils/vespa_cluster_status -t storage book
=== status of storage ===
| node | status | bucket-count | uniq-doc-count | uniq-doc-size |
|------|-------------|--------------|----------------|---------------|
| 0 | up | 7 | 7 | 5079 |
| 1 | up | 11 | 11 | 7665 |
| 2 | up | 8 | 8 | 5272 ||
実際にドキュメントの情報が |
実際に検索すると、初めに登録していた13件のドキュメントが取得できることがわかります。
$ curl 'http://localhost:8080/search/?query=sddocname:book'
{"root":{"id":"toplevel","relevance":1.0,"fields":{"totalCount":13}, ...6.2. クラスタの状態管理
Vespa のクラスタを運用する上で、クラスタ内の各ノードの状態を把握することが重要です。 ここでは、Vespa で提供されているコマンドを用いてクラスタの状態を管理する手順について説明します。
6.2.1. 状態管理の仕組み
Vespa では
Cluster Controller
と呼ばれるコンポーネントが各ノードの状態を管理しています。
Cluster Controller は services.xml の
admin セクションの cluster-controllers で定義していたサーバのことで、
Vespa クラスタ全体の状態管理を担当しています。
|
実際にはチュートリアルの設定では |
公式ドキュメントの図
のように、Cluster Controller の動作の流れは以下の通りです。
{kind=link}
-
slobrok(Service Location Broker) からノードのリストを取得 -
各ノードに対して現在の状態を問い合わせ (
u/d/m/rは後述のノード状態に対応) -
得られた情報から最終的なクラスタの状態を更新して全体に通知
チュートリアルの例では Cluster Controller は一つのみ指定していますが、
複数指定して冗長構成を取ることも可能です。
|
slobrok は各サービスがどこのホストのどのポートで動作しているかを管理するコンポーネントです。 vespa-model-inspect
コマンドを用いると |
|
マスターの選別は |
6.2.2. ノードの状態
Vespa クラスタのノードは Cluster and node states にあるように6つの状態を取りますが、運用上で使うのは起動処理中と停止処理中を除いた以下の4つです。
| 状態 | 意味 | 分散検索の対象? | 分散配置の対象? |
|---|---|---|---|
up |
サービスが提供可能。 |
o |
o |
down |
サービスが提供不可能。 |
x |
x |
maintenance |
メンテナンス中。 |
x |
o |
retired |
退役済み。 |
o |
x |
|
4つと言いましたが、実運用では |
表のように、4つはドキュメントの分散検索および分散配置の対象となるかどうか、という観点で動作が異なります。
up と down は非常にシンプルで、それぞれ全ての対象となるか完全に除外されるかに対応します。
maintenance は分散検索の対象からは外れますが、分散配置の対象にはなる、という動作をします。
maintenance はソフトウェアの更新作業など、比較的短いメンテナンス作業を行うときの指定が想定された状態で、
少しの間だけなので状態更新に伴うドキュメント再分散の負荷を避けたい、というときに利用します。
retired は分散検索の対象は維持しますが、分散配置の対象から外れる、という動作をします。
retired では分散配置の対象から外れるため、
状態更新後にノード上にあるドキュメントは0件になるまで (低優先度で) クラスタ内の他のノードへの再分配されていきます。
一方で、retired では分散検索の対象にはなるため、
サービスは提供しながら徐々に担当ドキュメントを別ノードへ逃がしていき、
最終的に0件となったところで役割を終えて引退させる、というような使い方をします。
各ノードの状態は vespa-get-node-state というコマンドを用いて取得できます。
[root@vespa1 /]# vespa-get-node-state -i 0 (1)
Shows the various states of one or more nodes in a Vespa Storage cluster. There
exist three different type of node states. They are:
Unit state - The state of the node seen from the cluster controller.
User state - The state we want the node to be in. By default up. Can be
set by administrators or by cluster controller when it
detects nodes that are behaving badly.
Generated state - The state of a given node in the current cluster state.
This is the state all the other nodes know about. This
state is a product of the other two states and cluster
controller logic to keep the cluster stable.
book/distributor.0: (2)
Unit: up:
Generated: up:
User: up:
book/storage.0: (3)
Unit: up:
Generated: up:
User: up:| 1 | distribution-key=0 のノード (-i 0) の状態を取得 |
| 2 | distributor (ドキュメント分散を行うコンポーネント) の状態 |
| 3 | storage (ドキュメント保持を行うコンポーネント) の状態 |
また、クラスタ全体の状態は vepsa-get-cluster-state というコマンドで確認できます。
[root@vespa1 /]# vespa-get-cluster-state
Cluster book:
book/distributor/0: up
book/distributor/1: up
book/distributor/2: up
book/storage/0: up
book/storage/1: up
book/storage/2: up6.2.3. ノード状態の判定
Vespa では、ノードの状態は
-
システム的に判断した状態 (
Unit state) -
ユーザが明示的に指定した状態 (
User state)
の2つの情報から最終状態 (Generated state) が判断されます。
Unit state
Unit state はプロセスの状態から機械的に判断される状態のことです。
例えば以下のように vespa2 の Docker コンテナを停止されると、
vespa2 に対応する distribution-key=1 のノードの Unit が down に更新されます。
$ sudo docker-compose stop vespa2 (1)
Stopping vespa2 ... done
$ sudo docker-compose exec vespa1 /bin/bash (2)
[root@vespa1 /]# vespa-get-node-state -i 1 (3)
...
book/distributor.1:
Unit: down: Connection error: Closed at other end. (Node or switch likely shutdown) (4)
Generated: down: Connection error: Closed at other end. (Node or switch likely
shut down)
User: up:
book/storage.1:
Unit: down: Connection error: Closed at other end. (Node or switch likely shutdown) (5)
Generated: down: Connection error: Closed at other end. (Node or switch likely
shut down)
User: up:| 1 | vespa2 の Docker コンテナを停止 |
| 2 | vespa1 の Docker コンテナにログイン |
| 3 | vespa2 (distribution-key=1) の状態を確認 |
| 4 | distributor の Unit state が down に変化 |
| 5 | storage の Unit state が down に変化 |
User state
User state はユーザが明示的に指定したノードの状態のことで、
vespa-set-node-state コマンドを利用して指定します。
例えば、vespa3 ノードのハードウェアが不調で、Vespa クラスタから明示的に外す (down にする) 場合は、
以下のようなコマンドとなります。
[root@vespa1 /]# vespa-set-node-state -i 2 down "hardware trouble" (1)
{"wasModified":true,"reason":"ok"}OK
{"wasModified":true,"reason":"ok"}OK
[root@vespa1 /]# vespa-get-node-state -i 2 (2)
...
book/distributor.2:
Unit: up:
Generated: down: hardware trouble
User: down: hardware trouble (3)
book/storage.2:
Unit: up:
Generated: down: hardware trouble
User: down: hardware trouble (4)| 1 | vespa3 (distribution-key=2) の状態を hardware trouble という理由で down に変更 |
| 2 | vespa3 (distribution-key=2) の状態を確認 |
| 3 | distributor の User state が down に変化 |
| 4 | storage の User state が down に変化 |
なお、vespa-set-node-state では上記例のように、第2引数でメモを付けることができます (省略も可)。
|
ノードの状態を明示的に変更することは、 例えば不調なノードが意図せず起動してしまったときに Vespa クラスタに参加させないようにする、 といった意図しない状態更新を抑止する効果があります。 |
|
|
6.3. ドキュメントの分散
Vespa ではドキュメントを
bucket
と呼ばれる単位に分割されて管理されます。
bucket という細かい粒度でドキュメントの冗長性を管理することで、
Vespa ではノード増減に対する高い柔軟性を担保しています。
|
公式ドキュメントでは Vespa elasticity にVespaの柔軟性に関する情報がまとめられています。 |
6.3.1. Distributor と SearchNode
ドキュメントの分散は、ノード状態の話で名前のでてきた Distributor と Storage という2つのコンポーネントが関わってきます。
なお、
公式ドキュメント
では Storage は SearchNode と呼ばれているため、
ここでは SearchNode と呼んでいきます。
|
より具体的なプロセス名だと、
|
Distributor はドキュメントの分散を担当するコンポーネントで、
各 bucket のチェックサムや割り振り先などのクラスタ全体での bucket の一貫性の担保に関わる情報を管理しています。
Distributor は services.xml で指定された冗長数と Cluster Controller から得られるクラスタの状態を元に、
各 bucket がどこに配置されるべきか、再分配が必要なのか、といったことを判断します。
SearchNode は実際にインデックスへのアクセスを担当するコンポーネントで、
bucket の本体を保持しています。
SearchNode では Vespa の永続化や検索といった検索エンジンのコア実装が含まれています。
|
|
6.3.2. bucket の配置と再分配
bucket の配置は、以下のように各ノードに対して乱数を生成し、
それをソートした順番をもとに優先順位を決めることで行われます。
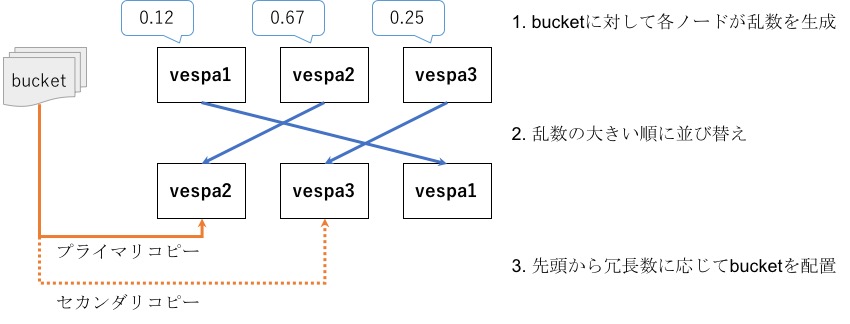
|
分散アルゴリズムのより詳しい話は Distribution algorithm を参照してください。 |
得られたノード番号 (distribution-key) 列のうち、一番先頭のノードに bucket のプライマリコピーが、
冗長数に応じてそれ以降のノードに bucket のセカンダリコピーが配置されます。
Vespa ではこのルールに従い、ノードが増減したときの bucket の再分配が行われます。
例えば、冗長数が 2 の状態でノードが増減したときに bucket の動きは以下のようになります。
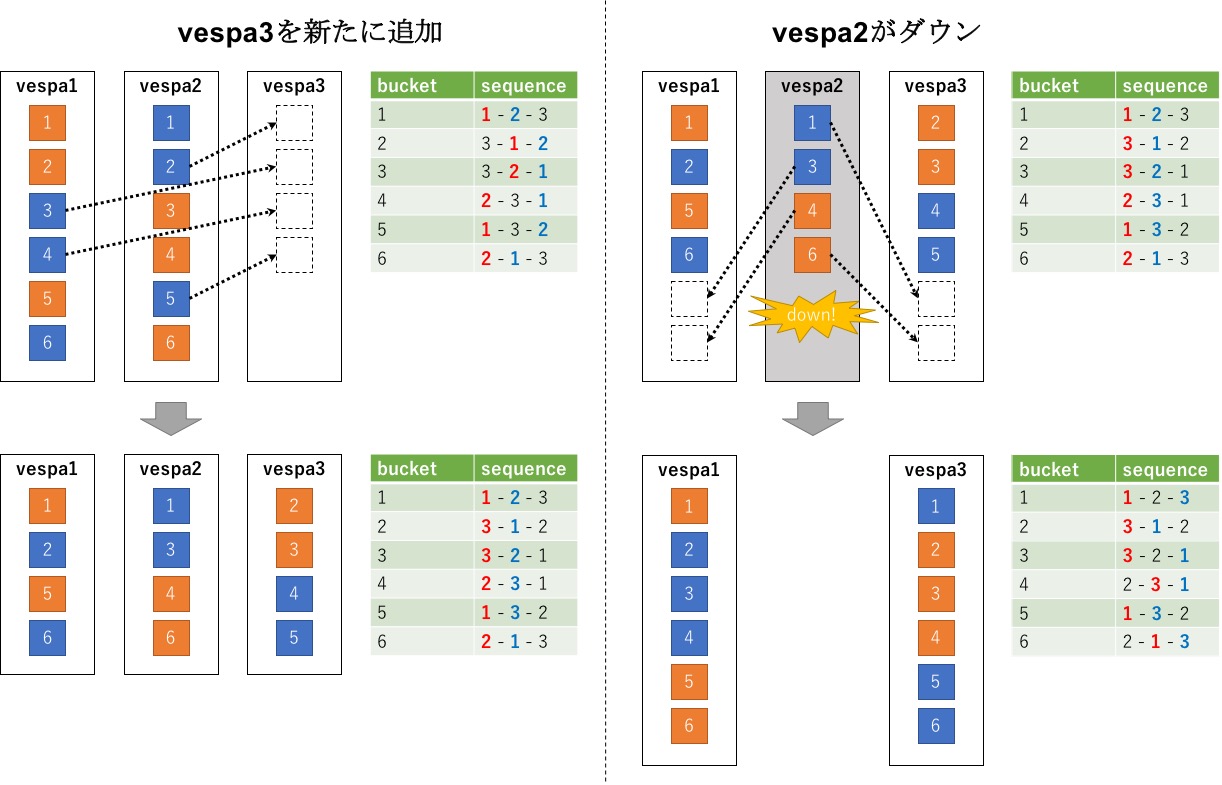
|
各 |
6.3.3. チュートリアル環境での例
チュートリアルの Vespa クラスタを用いて、 実際にノードを増減させた場合にどのような動作をするか見ていきます。 クラスタにドキュメントを全件追加したときの状態は以下のようになっていました。
$ utils/vespa_cluster_status -t storage book
=== status of storage ===
| node | status | bucket-count | uniq-doc-count | uniq-doc-size |
|------|-------------|--------------|----------------|---------------|
| 0 | up | 7 | 7 | 5079 |
| 1 | up | 11 | 11 | 7665 |
| 2 | up | 8 | 8 | 5272 |ここで、試しに vespa2 (上図の node=1) の Docker コンテナを停止させると、
vespa2 のドキュメントが他の2つのノードに分配されることが確認できます。
$ sudo docker-compose stop vespa2 (1)
Stopping vespa2 ... done
$ utils/vespa_cluster_status -t storage book (2)
=== status of storage ===
| node | status | bucket-count | uniq-doc-count | uniq-doc-size |
|------|-------------|--------------|----------------|---------------|
| 0 | up | 13 | 13 | 9008 |
| 1 | down | 0 | 0 | 0 |
| 2 | up | 13 | 13 | 9008 || 1 | vespa2 の Docker コンテナを停止 |
| 2 | vespa2 (node=1) が担当していた11件が他の2ノードに再分配 |
|
停止させた直後は |
次に、停止させた vepsa2 を再び起動させると、
3つのノードに再分配されて元の状態に戻ることが確認できます。
$ sudo docker-compose start vespa2 (1)
Starting vespa2 ... done
$ utils/vespa_cluster_status -t storage book (2)
=== status of storage ===
| node | status | bucket-count | uniq-doc-count | uniq-doc-size |
|------|-------------|--------------|----------------|---------------|
| 0 | up | 7 | 7 | 5079 |
| 1 | up | 11 | 11 | 7665 |
| 2 | up | 8 | 8 | 5272 || 1 | vespa2 の Docker コンテナを起動 |
| 2 | 3ノードに再分配されて初めの状態に戻る |
6.4. その他のトピック
6.4.1. ログの確認
Vespa の起動
で紹介した構成図のように、
Vespa では各サービスのログは log server に集約されます。
そのため、log server のログを参照することで、クラスタ全体のログを確認できます。
|
|
log server では、以下のように /opt/vespa/logs/vespa/logarchive/ の下にログが集約されています。
[root@vespa1 /]# tree /opt/vespa/logs/vespa/logarchive/
/opt/vespa/logs/vespa/logarchive/
└── 2018
└── 02
└── 23
└── 04-0Vespa のログを見るときは
vespa-logfmt
を使うと便利です。
vespa-logfmt は、以下のようにオプションとして多数のログのフィルタが提供されています。
[root@vespa1 /]# vespa-logfmt -h
Usage: /opt/vespa/bin/vespa-logfmt [options] [inputfile ...]
Options:
-l LEVELLIST --level=LEVELLIST select levels to include
-s FIELDLIST --show=FIELDLIST select fields to print
-p PID --pid=PID select messages from given PID
-S SERVICE --service=SERVICE select messages from given SERVICE
-H HOST --host=HOST select messages from given HOST
-c REGEX --component=REGEX select components matching REGEX
-m REGEX --message=REGEX select message text matching REGEX
-f --follow invoke tail -F to follow input file
-L --livestream follow log stream from logserver
-N --nldequote dequote newlines in message text field
-t --tc --truncatecomponent chop component to 15 chars
--ts --truncateservice chop service to 9 chars
FIELDLIST is comma separated, available fields:
time fmttime msecs usecs host level pid service component message
Available levels for LEVELLIST:
fatal error warning info event debug spam
for both lists, use 'all' for all possible values, and -xxx to disable xxx.vespa-logfmt を引数なしで実行すると、
デフォルトではノードで起動しているサービスのアプリケーションログに対応する
/opt/vespa/logs/vespa/vespa.log が参照されます。
[root@vespa1 /]# vespa-logfmt | tail -3
[2018-02-23 04:14:48.700] INFO : container-clustercontroller Container.com.yahoo.vespa.clustercontroller.core.database.ZooKeeperDatabase Fleetcontroller 0: Storing new cluster state version in ZooKeeper: 10
[2018-02-23 04:14:58.612] INFO : container-clustercontroller Container.com.yahoo.vespa.clustercontroller.core.SystemStateBroadcaster Publishing cluster state version 10
[2018-02-23 04:46:40.991] INFO : container-clustercontroller stdout [GC (Allocation Failure) 232656K->16316K(498112K), 0.0054783 secs]Vespa クラスタ全体のログを見る場合は、引数の inputfile として先程のアーカイブログを指定する必要があります。
例えば、vespa2 ノードの warning レベルのログが見たい場合は以下のようなコマンドとなります。
[root@vespa1 /]# vespa-logfmt -l warning -H vespa2 /opt/vespa/logs/vespa/logarchive/2018/02/23/04-0 | tail -3
[2018-02-23 04:14:35.944] WARNING : searchnode proton.searchlib.docstore.logdatastore We detected an empty idx file for part '/opt/vespa/var/db/vespa/search/cluster.book/n1/documents/book/2.notready/summary/1519358811014181000'. Erasing it.
[2018-02-23 04:14:35.944] WARNING : searchnode proton.searchlib.docstore.logdatastore Removing dangling file '/opt/vespa/var/db/vespa/search/cluster.book/n1/documents/book/1.removed/summary/1519358811013672000.dat'
[2018-02-23 04:14:35.944] WARNING : searchnode proton.searchlib.docstore.logdatastore Removing dangling file '/opt/vespa/var/db/vespa/search/cluster.book/n1/documents/book/2.notready/summary/1519358811014181000.dat'|
チュートリアルの例では時間が標準時間となっていますが、
これは起動している環境のタイムゾーンが タイムゾーンを |
6.4.2. メトリクスの取得
Vespa では、検索レイテンシなどのメトリクスを取得するための Metrics API が提供されています。
Metrics API が提供されているポートはサービスによって異なります。
各サービスで提供されているポートは
vespa-model-inspect
コマンドを使うことで確認できます。
[root@vespa1 /]# vespa-model-inspect service container (1)
container @ vespa1 :
container/container.0
tcp/vespa1:8080 (STATE EXTERNAL QUERY HTTP) (2)
tcp/vespa1:19100 (EXTERNAL HTTP)
tcp/vespa1:19101 (MESSAGING RPC)
tcp/vespa1:19102 (ADMIN RPC)
container @ vespa2 :
container/container.1
tcp/vespa2:8080 (STATE EXTERNAL QUERY HTTP)
tcp/vespa2:19100 (EXTERNAL HTTP)
tcp/vespa2:19101 (MESSAGING RPC)
tcp/vespa2:19102 (ADMIN RPC)
container @ vespa3 :
container/container.2
tcp/vespa3:8080 (STATE EXTERNAL QUERY HTTP)
tcp/vespa3:19100 (EXTERNAL HTTP)
tcp/vespa3:19101 (MESSAGING RPC)
tcp/vespa3:19102 (ADMIN RPC)
[root@vespa1 /]# vespa-model-inspect service searchnode (3)
searchnode @ vespa1 : search
book/search/cluster.book/0
tcp/vespa1:19109 (STATUS ADMIN RTC RPC)
tcp/vespa1:19110 (FS4)
tcp/vespa1:19111 (UNUSED)
tcp/vespa1:19112 (UNUSED)
tcp/vespa1:19113 (STATE HEALTH JSON HTTP) (4)
searchnode @ vespa2 : search
book/search/cluster.book/1
tcp/vespa2:19108 (STATUS ADMIN RTC RPC)
tcp/vespa2:19109 (FS4)
tcp/vespa2:19110 (UNUSED)
tcp/vespa2:19111 (UNUSED)
tcp/vespa2:19112 (STATE HEALTH JSON HTTP)
searchnode @ vespa3 : search
book/search/cluster.book/2
tcp/vespa3:19108 (STATUS ADMIN RTC RPC)
tcp/vespa3:19109 (FS4)
tcp/vespa3:19110 (UNUSED)
tcp/vespa3:19111 (UNUSED)
tcp/vespa3:19112 (STATE HEALTH JSON HTTP)| 1 | container サービス (検索リクエストを受けるところ) のポートを確認 |
| 2 | vespa1 ノードでは 8080 ポート |
| 3 | searchnode サービス (インデックスを管理してるところ) のポートを確認 |
| 4 | vespa1 ノードでは 19113 ポート |
実際に Metrics API を用いると、以下のように json 形式でメトリクスが取得できます。
[root@vespa1 /]# curl 'http://localhost:8080/state/v1/metrics'
{
"metrics": {
"snapshot": {
"from": 1.519363748005E9,
"to": 1.519363808005E9
},
"values": [
{
"name": "search_connections",
"values": {
"average": 0,
"count": 1,
"last": 0,
"max": 0,
"min": 0,
"rate": 0.016666666666666666
}
},
...返却されるメトリクスは snapshot に書かれた期間でのスナップショットに対応しており、
デフォルトのインターバルは container ノードが 300秒 が、
searchnode ノードが 60秒 (たぶん) となっています。
各メトリクスは values として複数の値を返しますが、共通の項目は以下のように定義されます。
| 項目 | 内容 |
|---|---|
count |
期間中にメトリクスが計測された回数。 |
average |
期間中のメトリクスの平均値 ( |
rate |
1秒あたりの計測回数 ( |
min |
期間中の最小値。 |
max |
期間中の最大値。 |
sum |
期間中のメトリクスの総和。 |
各サービスで色々なメトリクスが出力されますが、例えば以下のようなメトリクスがとれます。
| 項目 | サービス | 内容 |
|---|---|---|
queries |
container |
クエリの処理数、 |
query_latency |
container |
検索レイテンシの統計値。 |
proton.numdocs |
searchnode |
インデックスされているドキュメント数。 |
|
具体的なメトリクス周り公式ドキュメントが このあたり しかなく、正直どれがどれに対応しているかはコードを確認する必要があるのが現状です。。。 実際のサービスだとこれに加えて更新リクエストの方もチェックしていましたが、
それは投げる側でモニタリングしていたため、Vespa の |
|
ただ、実際のところ |
7. Solr/Elasticsearch との機能比較
このセクションでは、Vespa と他の検索エンジンを比べて、 具体的にどのような差異があるのか見ていきます。
|
著者の個人的な見解がかなり含まれます。 |
|
Vespaの公式ページ の下の方にも機能比較表があります。 |
ここでは、比較対象として Solr と Elasticsearch の2つを取り上げます。 Solr と Elasticsearch は共に Lucene をコアとする検索エンジンで、 世界的にも多くの利用実績がある代表的な OSS の一つです。
|
チュートリアルには |
7.1. スキーマと更新
7.1.1. 動的フィールド
Solr/Elasticsearch と Vespa のスキーマ定義を比較したとき、 大きな違いの一つとして動的フィールドのサポートの有無があります。
Solr では dynamic fields を、
Elasticsearch では dynamic templates を使ってインデックスされたフィールド名に応じて動的にフィールドを追加することができます。
この機能によって、Solr/Elasticsearch ではスキーマに縛られにくい柔軟なインデクシングを可能としています。
特に、Elasticsearch では
Object datetype
のようにかなり自由なデータをインデクシングできるのが特徴です。
一方、Vespa では前述のような動的フィールドに対応する機能は現状では提供されていません。 そのため、ユーザは事前にスキーマ設計をしっかりと行うことが求められます。
サービスとして検索エンジンを使う場合、 一般的にスキーマ設計を行うはずなので双方であまり差異はありませんが、 データストアとして検索エンジンを使う場合は、 動的フィールドが可能な Solr/Elasticsearch の方が柔軟性が高いと考えられます。
|
データストア・アナリシス的な用途なら Elastic Stack が有名かと思います。 |
7.1.2. データ型
Vespa、Solr/Elasticsearch ともに基本的なデータ型については大きな差異はありません。 2つで動作が大きく異なるケースとして、配列のような多次元の値を扱う場合があげられます。
Vespa では
searchdefinitions
で述べたように、array と weightedset という2つの型をサポートしています。
Vespa での複数値は、
attribute
といった関数を用いてインデックスやキーで各値に個別アクセスができ、
値の順序 (例えば階層構造とか) に意味を持たせることができます。
また、Vespa では
テンソルを用いたスコア計算
で述べたテンソル型という高次元のデータ型を保持することができ、
近年注目を集めている分散表現やディープライーニングといった先進技術との親和性が高いことも大きなポイントです。
一方、Solr/Elasticsearch の場合、配列型以外については設計を工夫する必要があります。
チュートリアルの例では、前述の動的フィールドを用いてマッピングを行うことで Vespa の weightedset の代替としています。
この方法では、キーとなる新しい値が登録されるたびに裏側では新しいフィールドが定義されることとなるため、
キーのバリエーションが非常に多いケースを扱うことが困難です。
また、高次元ベクトルを検索で扱う場合に、Solr/Elasticsearch ではまだ適切なデータ型がないように感じます。
|
Solr/Elasticsearch の配列は、インデックス上では投入順序が保持されないという特徴があります。
これは、内部で利用している Lucene の |
|
Solr/Elasticsearch でも拡張フィールドを独自実装すれば、 |
7.1.3. リアルタイム性
Solr/Elasticsearch の基盤となっている Lucene では、
softCommit と hardCommit という2つのコミットによってインデックスを管理します。
前者は更新内容を検索できるようにするもの、後者は更新内容をディスクに永続化するものに対応します。
Solr/Elasticsearch では、この softCommit の間隔を制御することで Near Real Time (NRT) 検索を実現しています (
Solr、
Elasticsearch
)。
より高いリアルタイム性が必要な場合、この softCommit の間隔をチューニングすることになりますが、
softCommit では Searcher と呼ばれる検索を担当するインスタンスの再生成が走るため、
実行にある程度のコストがかかります。
そのため、softCommit の頻度が検索などのパフォーマンスに影響を与え、
性能要件によっては短い時間を設定することが困難な場合が多いです。
Vespa では公式ドキュメントの Features や Vespa consistency model で述べられているように、 更新リクエストのレスポンスが返ったタイミングで検索の対象となるように設計されています。 そのため、ドキュメント更新のリアルタイム性が非常に高い検索エンジンといえます。
|
Vespa のインデクシングの中身の詳細については公式ドキュメントが特になかったため、 ここでは上記 Vespa のドキュメントでの謳い文句と運用での経験ベースに話をしています。 Vespa のインデックスのざっくりとした流れは
Vespa search sizing guide
の |
7.2. 検索周り
7.2.1. 集約処理
単純な検索機能については Vespa と Solr/Elasticsearch では大きな差はないですが、 集約処理については Vespa と Solr/Elasticsearch で差異があります。
検索結果を羅列する grouping という観点では、
Vespa と Elasticsearch については大きく差異はない印象です。
Vespa なら
グルーピング検索
で紹介したように、
Query result grouping reference
に記載された DSL を用いて多段グルーピングができ、
Elasticsearch も
Aggregations
の
top_hits
を組み合わせることで多段グルーピングが可能です。
|
Solr は多段グルーピングをサポートしていません。 また、 Field Collapsing については集約処理とは若干用途が異なるので議論の対象から外しています。 |
一方、グループ内でのソートでは、Vespa は
Vespa とランキング
で紹介した rank-profile の定義をそのままグループ内のリランキングに適用できるため、
Solr/Elasticsearch に比べてグループ内の上位をより精度よく選択することができます。
各グループの統計値といった特定の側面を計算する faceting という観点では、
Solr/Elasticsearch の方が Vespa に比べて機能が豊富のように感じます。
前述の DSL のお陰で Vespa は faceting でも様々な集約条件を定義できます。
一方、Solr では
Streaming Expressions
を用いることで、検索結果をストリーミング処理の要領で細かく加工することが可能です。
また、Elasticsearch も
Aggregations
で紹介されているような多くの集約処理があったり、
Scripting
で細かい調整が可能だったりと高機能です。
7.2.2. 高度な検索機能
その他の検索 で紹介したように、 WAND 検索、Predicate フィールド と Vespa には Solr/Elasticsearch にはない検索機能があります。
|
位置検索は Solr/Elasticsearch にもあります。 また、ストリーミング検索については Solr/Elasticsearch のワイルドカードクエリと対応します。 |
Predicate フィールドについては、Elasticsearch では Percolate Query という似た機能が存在しますが、Percolate Query ではクエリをインデックスに登録して入力ドキュメントに対して当てるという動作なのに対し、 Vespa の Predicate フィールドは各ドキュメントのフィールド値として条件式を埋め込むため、 各ドキュメントを個別に制御できる点が異なります。
これらの機能は単純な全文検索ではなかなか使うタイミングがありませんが、 レコメンド、広告、メールなど具体的にターゲットを絞った場合に恩恵を受けられるケースがあるかもしれません。
7.3. ランキング
7.3.1. フェーズ分け
検索エンジンのコア機能を使って任意のスコア式を記述する場合、 Solr は FunctionQuery を、Elasticsearch は FunctionScoreQuery を用いてスコアを定義します。 また、最近では上位の結果をリランキングするプラグインとして Solr と Elasticsearch それぞれで LTR (Learning To Rank) プラグインが提供されています ( Solr、 Elasticsearch )。
|
Solr ではこれに加えて
ReRakQParserPlugin
と |
Vespa の
ランキングの流れ
と対応させると、
Solr の FunctionQuery および Elasticsearch の FunctionScoreQuery が first-phase に、
LTRプラグインが second-phase に対応します。
このように、Solr と Elasticsearch では2つのフェーズのランキングが別の機能として提供されます。
そのため、2つのフェーズでスコア式を記述する場合、別々に定義を書かなくてはならないというのがネックです。
それに対して、Vespa は rank-profile に全てまとめて定義できるため、
ランキングの定義は Vespa の方がスッキリしています。
7.3.2. 記述の自由度
単純な記述の自由度という観点では、
最も自由度が高いのは
Scripting
を用いて Groovy ライクに書ける Elasticsearch の Function Score Query かと思います。
ただし、Scripting ではいわゆる素性が扱えないため、
高度なモデルを定義したい場合にネックになると考えられます。
|
|
一方、Solr と Elasticsearch の LTR プラグインでは、
検索クエリを素性として定義できるため、より精度の高いモデルを定義できます。
ただ、こちらはデフォルトで利用できるモデルの型が線形モデルとアンサンブル木に限定されており、
チュートリアルの price_boost のような独自の数式を書きたい場合は、
別途対応するモデルを実装する必要があるというのが難点です。
Vespa はランク式を DSL として提供しつつ、
組み込み素性
で紹介したように様々なランク素性が利用できるため、自由に高度なモデルの記述が可能です。
また、検索クエリを使う LTR プラグインと異なり、これらランク素性はコードとして実装されているため動作が速いのも特徴です。
ただし、組み込みの素性以外を使いたいという場合、rank-profile のマクロとして数式の定義はできますが、
全く新しい素性を実装して追加するためには検索コアの実装に手を加える必要があり、難易度が高いです。
7.3.3. 高度なランキング
テンソルを用いたスコア計算 で紹介したテンソルへの対応は、Vespa がもつ非常に強力な機能です。 内積や行列演算は state-of-the-art な手法をランキングで用いたい場合に必要になる機能なので、 検索エンジンが標準でそれをサポートしている意味は大きいです。
また、 WAND 検索 もランキングの視点で見ると疎ベクトルの内積計算に対応しており、 Vespa の持つ高度なランキング機能の一つと捉えることができます。
WAND 検索については、 Solr/Elasticsearch でも payload でテキストの単語に重みを埋め込み、 検索クエリにブースト値を付与してスコア計算に組み込めば似たようなことは可能です。 ただし、WAND 検索のような賢い枝刈りアルゴリズムがないため、Vespa より速度がでないと思います。
|
最近では Solr コミュニティで DL4J を LTR プラグインに組み込もうという動きもあります ( SOLR-11838 )。 |
7.4. スケーラビリティ
7.4.1. 分散インデクシング
Vepsa は
ドキュメントの分散
でも述べたように、ドキュメントを bucket という細かい粒度で分散させるのが特徴で、
ここは Solr/Elasticsearch と大きく異なる点の一つです。
Solr/Elasticsearch では、クラスタ上でのインデックスの分割数 (シャード数) を事前に決めて分散インデクシングを行います。 このシャード数は、一度決めると容易にその数を変更することができず、 変更する場合はシャードの分割やインデックスの再構築が必要となります。
一方、Vespa は bucket というより細かい粒度でドキュメントを管理しており、
その分割数も状況によって増減します。
そのため、ユーザはインデックスの冗長数 (Solr/Elasticsearch のレプリカ数) だけを意識すればよく、
分散インデクシングの管理が非常に容易かつ効率的に行うことができます。
ドキュメントを細かい粒度で分散させることは、障害時のパフォーマンスという観点でも有意性があります。
Solr/Elasticsearch の場合、特定のノードがダウンすると、
本来そのノードが処理するはずだったリクエストを対応するレプリカを持つノード群が肩代わりします。
そのため、障害時に特定のノードのリクエスト数が 1 + 1/#replicas 倍に増加することになります。
一方、Vespa の場合、特定のノードがダウンしたとしても、対になる bucket はクラスタ全体に分散しているため、
ダウンしたノードのリクエストをクラスタ全体でカバーすることができ、
リクエスト数の増加を 1 + 1/#nodes 倍に抑えることができます。
基本的に #nodes > #replicas となるため、障害時の負荷増加は Vespa の方が小さくなります。
7.4.2. ノードの追加・削除
クラスタへのノードの追加・削除も、 Vespa では非常に簡単に行うことができます。
Solr/Elasticsearch の場合、前述のようにシャード数が変更できないため、 ノードの増減にあわせてシャード/レプリカ単位での再分配を行うことになります。 この作業は、Elasticsearch の場合、再分配は自動で行われますが、Solr の場合は現状手作業で行う必要があります。 シャード自体の分割が困難なため、ノード追加・削除が発生した場合、 場合によってはシャード数を再設計して再インデックスする必要があります。
Vespa では、
クラスタ設定の反映
の例で示したように、services.xml と hosts.xml に追加・削除するノードの情報を追記して反映させるだけで、
Vespa が bucket の再分配を行ってくれます。
また、Solr/Elasticsearch のようにシャード数を気にする必要もないため、
カジュアルにノードの増減を行うことが可能です。
7.5. 拡張性
7.5.1. 多言語対応
多言語対応という点では、現状 Vespa は Solr/Elasticsearch に比べると大きく差があります。
Solr/Elasticsearch は世界的に利用実績があるため、現状で多くの言語をサポートしています。
また、Solr/Elasticsearch の言語処理は、
入力文字列の1文字1文字に変換を加える CharFilter、
文字列をトークン分けする Tokenizer、
トークン毎に変換を加える TokenFilter
の3つのクラスの組み合わせによって定義されます (
Solr、
Elasticsearch
)。
そのため、これらの組み合わせ方によって言語処理フローを柔軟に構築できるというのも特徴の一つです。
一方、Vespa は OSS としてまだ若いこともあり、公式でサポートしている言語は今のところ英語圏に限られています。
Vespa では
Linguistics
というクラスを拡張することで対応言語を増やすことができます。
Solr/Elasticsearch とは異なり、
Vespa ではステミングや正規化といった処理も Lingusitics の中に内包させます。
幸い、今回使用した KuromojiLinguistics のように、
既存のパッケージを組み合わせれば対応自体はそこまで難しくはないので、
今後ユーザが増えていって多言語対応の差自体が埋まっていくことを期待します。
7.5.2. プラグインの追加
Solr/Elasticsearch は、 世の中にサードパーティ製のプラグインがたくさんあることからも分かるように、 拡張性が高い検索エンジンとなっています。 また、Solr/Elasticsearch は Pure Java で実装された検索エンジンなので、 機能開発の敷居も比較的低いといえます。
Vespa でプラグインを追加する場合は、基本的に
container
にプラグインを追加していく形になります。
典型的な拡張は、
検索リクエスト/レスポンスの加工を行う Searcher、
更新リクエストの加工を行う DocumentProcessor の追加です。
これらはサーブレット・フィルタのようにチェインさせてパイプライン処理させるように利用します(
Container component types
)。
また、Vespa の container は
JDisc
(Java Data Intensive Serving Container) というフレームワークの上で動作しており、
内部で独自のサーバを立てたり、DI コンテナでインジェクトするインスタンスを差し替えたりと、
色々自由に動作を変えることができます。
|
前述の |
一方、Vespa の検索コアは proton と呼ばれる C++ のパッケージとなっており、 こちらに機能を追加したい場合はコードを実装して再ビルドする必要があります。 そのため、検索コアの深いところまで手を加えたい場合、 Vespa は Solr/Elasticsearch に比べると実装難易度が高いです。
7.6. まとめ
ここまで述べてきた Vespa と Solr/Elasticsearch の特徴を、 公式サイト の表のようにまとめると以下のようになります。
| 特徴 | Vespa | Solr/Elasticsearch | 備考 |
|---|---|---|---|
データ解析 |
☆ |
☆☆☆ |
|
全文検索 |
☆☆☆ |
☆☆ |
|
ランキング |
☆☆☆ |
☆ |
|
スケーラビリティ |
☆☆☆ |
☆☆ |
|
拡張性 |
☆☆ |
☆☆☆ |
|
見解としては公式サイトでの表と同じで、全文検索がしたいなら Vespa はよい選択肢になると思います。 逆に、データ解析での利用を検討している場合は、Elastic Stack のようなパッケージを利用した方が効率的かと思います。
機能面では、まずランキング機能が Solr/Elasticsearch と比べてかなり先進的で、 特にテンソルが扱えることで、近年話題の Deep Learning 系の技術を取り込める点は大きな強みです。 また、ドキュメント分散の仕組みが賢く、スケールアウトが容易な点も、 特に大規模なクラスタを組むようなケースで大きなポイントになるかと思います。
一方、拡張性という観点では、OSS としてまだ若いこともあり、 Solr/Elasticsearch に比べてサードパーティ製のプラグインなどのオプションが少ないところはネックかと思います。 Vespa 自体の拡張性は JDisc のおかげで非常に高いのですが、 個人的には検索コアに手が入れにくいところが気になる部分で、 このため拡張性については公式サイトと優劣を逆につけています。